





最近,谷歌DeepMind和斯坦福的研究人员发现:大模型在处理逻辑推理任务时,问题中信息呈现的顺序对模型的表现有着决定性的影响。

论文地址:https://arxiv.org/abs/2402.08939
具体来说,当信息按照逻辑上的自然顺序排列时,模型的表现会更好。这一发现不仅适用于一般的逻辑推理问题,对于数学问题也同样有效。
比如,如果某个证明任务的条件是:
1. 如果A,那么B;
2. 如果B,那么C;
3. A为真。
要求大模型证明C为真,如果条件按照1,2,3的顺序呈现,那么大模型的成功率会比2,1,3的条件呈现顺序高出很多。
所以,以后用大模型,言简意赅,符合逻辑地提出问题能让它性能更强。

上图展示了一个失败的案例,GPT-4,Gemini Pro,GPT-3.5在改变相关规则的顺序后都未能成功生成证明。

上图可以看出,对于当前主流的几个大模型,改变前提的叙述顺序都会导致性能大幅下降。
有趣的是,谷歌的新型模型Gemini Pro和OpenAI的GPT-3.5-Turbo,在下降趋势上几乎一样。
而且研究人员发现,如果进一步向上述逻辑推理任务中添加分散注意力的规则,打乱前提会导致更大的准确性下降。
实验中,研究人员通过将GSM8K测试集中的问题陈述顺序打乱,构建了GSM8K的变体——R-GSM测试集。
下图是其中一个例子,对于原本可以解决的问题,将前提顺序打乱之后(R-GSM),LLM就变得无能为力。

在R-GSM测试集中,几乎所有主流的LLM性能都出现了下降。

虽然人类在解决逻辑问题时,对前提顺序也会有偏好,但LLM「更容易」受到这种顺序效应的影响。
研究人员认为这可能是由于自回归模型训练目标和/或训练数据中的偏差造成的。
但如何应对这个问题仍然是一个有待进一步研究的挑战。
如果A是B,那么B也是A
众所周知,在逻辑推理中,改变前提条件的顺序并不会改变结论。
对于人类来说,在处理这类问题时也倾向于按照某种特定的顺序来排列前提,以便更好地推理。但这种偏好对解决问题的能力影响不大,尤其是在涉及到直接的逻辑推理(如果P,则Q、P;因此Q)时。
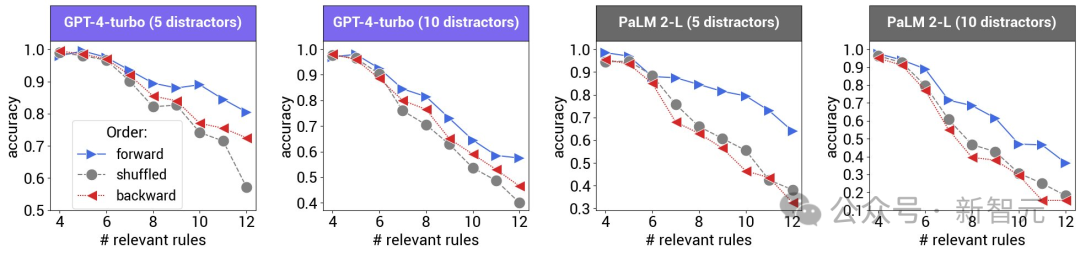
然而,对于大型语言模型来说,前提的顺序却极大地影响了它们的推理表现。
特别是,当前提的排列顺序与它们在正确证明中的出现顺序一致时,LLM的表现最好。
以刚才提出的简单任务为例,研究人员注意到两个现象:
1. 在提示中先提出「如果A则B」,然后是「如果B则C」,通常会比反过来的顺序有更高的准确率。
2. 当前提数量增多时,性能的差距会更加明显。
这种「乱序」的逻辑推理对人类来说很简单,但对语言模型而言却是一个重大的挑战。
研究发现,改变前提的顺序可以使模型的准确率下降超过30%。
而且有意思的是,不同的「乱序」对于不同的模型的影响也是完全不同的。
当前提的顺序与实际情况完全相反时,OpenAI的GPT模型表现得更好。这种方式使得模型能够通过从后向前的推理来进行推导。而PaLM 2-L在这种反向排序下的表现通常是最差的。
「逆序」评测基准R-GSM
为了进一步系统性地研究这个问题,研究人员在数学推理测试集GSM8K的基础之上开发了一个「乱序」测试集R-GSM。
具体来说,他们首先选择问题描述中至少有5个句子的GSM8K测试问题,然后过滤掉那些没法替换问题顺序的问题,例如遵循事件因果顺序的问题陈述系列。
对于剩下的每个问题,保持最后一句话不变,并用其他句子的不同顺序重写问题描述。允许对单词进行少量编辑,以确保问题描述的正确性。
而对GSM8K做这样的变化,原因是基于研究人员对于问题中前提顺序的看法和认知来进行调整的。
具体来说,研究人员将符合前向链式基本事实证明的顺序称为前向顺序,其中每个推导步骤中应用的规则在问题描述中依次呈现。
直观地说,按照前向顺序呈现前提对人类来说简化了问题,因为这允许人类在阅读前提的同时即时写出证明。
相反,如果前提排序更加随意,则会增加任务难度,因为在进行推导时,人类需要在每个推理步骤中重复查找前提。
受这种直觉的启发,他们根据不同前提顺序与前向顺序的Kendall tau距离



