






本文首先将关注 RAG 的概念和理论。然后将展示可以如何使用用于编排(orchestration)的 LangChain、OpenAI 语言模型和 Weaviate 向量数据库来实现一个简单的 RAG。
检索增强生成是什么?
检索增强生成(RAG)这一概念是指通过外部知识源来为 LLM 提供附加的信息。这让 LLM 可以生成更准确和更符合上下文的答案,同时减少幻觉。
问题
当前最佳的 LLM 都是使用大量数据训练出来的,因此其神经网络权重中存储了大量一般性知识(参数记忆)。但是,如果在通过 prompt 让 LLM 生成结果时需要其训练数据之外的知识(比如新信息、专有数据或特定领域的信息),就可能出现事实不准确的问题(幻觉),如下截图所示:

因此,将 LLM 的一般性知识与附加上下文整合起来是非常重要的,这有助于 LLM 生成更准确且更符合上下文的结果,同时幻觉也更少。
解决方案
传统上讲,通过微调模型,可以让神经网络适应特定领域的或专有的信息。尽管这种技术是有效的,但其需要密集的计算,成本高,还需要技术专家的支持,因此就难以敏捷地适应不断变化的信息。
2020 年,Lewis et al. 的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》提出了一种更为灵活的技术:检索增强生成(RAG)。在这篇论文中,研究者将生成模型与一个检索模块组合到了一起;这个检索模块可以用一个更容易更新的外部知识源提供附加信息。
用大白话来讲:RAG 之于 LLM 就像开卷考试之于人类。在开卷考试时,学生可以携带教材和笔记等参考资料,他们可以从中查找用于答题的相关信息。开卷考试背后的思想是:这堂考试考核的重点是学生的推理能力,而不是记忆特定信息的能力。
类似地,事实知识与 LLM 的推理能力是分开的,并且可以保存在可轻松访问和更新的外部知识源中:
- 参数化知识:在训练期间学习到的知识,以隐含的方式储存在神经网络权重之中。
- 非参数化知识:储存于外部知识源,比如向量数据库。
下图展示了最基本的 RAG 工作流程:
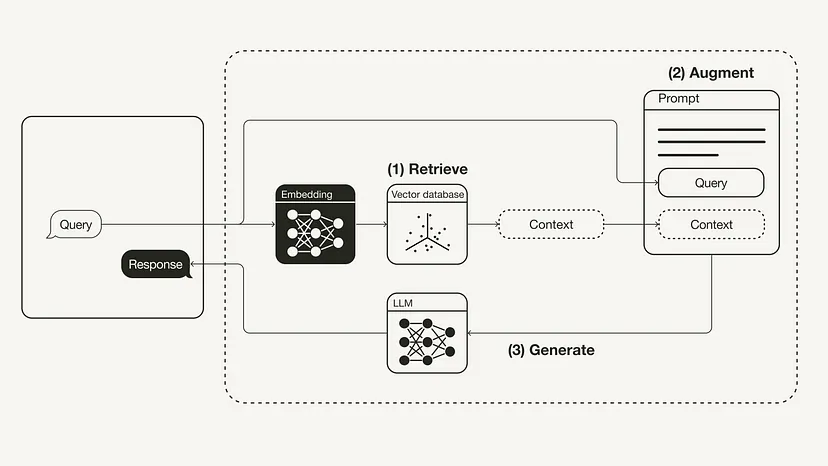
检索增强生成(RAG)的工作流程
- 检索:将用户查询用于检索外部知识源中的相关上下文。为此,要使用一个嵌入模型将该用户查询嵌入到同一个向量空间中,使其作为该向量数据库中的附加上下文。这样一来,就可以执行相似性搜索,并返回该向量数据库中与用户查询最接近的 k 个数据对象。
- 增强:然后将用户查询和检索到的附加上下文填充到一个 prompt 模板中。
- 生成:最后,将经过检索增强的 prompt 馈送给 LLM。
使用 LangChain 实现检索增强生成
下面将介绍如何通过 Python 实现 RAG 工作流程,这会用到 OpenAI LLM 以及 Weaviate 向量数据库和一个 OpenAI 嵌入模型。LangChain 的作用是编排。
必要前提
请确保你已安装所需的 Python 软件包:
- langchain,编排
- openai,嵌入模型和 LLM
- weaviate-client,向量数据库
#!pip install langchain openai weaviate-client分享说明:转发分享请注明出处。



