





作者 | 崔皓
审校 | 重楼
摘要
本文介绍了OpenAI的最新进展,重点关注其在多模态技术领域的突破。文章首先探讨了GPT-4 Turbo模型的优化和多模态功能的融合,如图像生成和文本到语音转换。随后,作者深入解析多模态技术的工作原理,特别是文本到图像的转换过程。通过实际应用和编程实例,展示了如何利用这些技术对图像和视频内容进行识别,以及将识别内容转换为语音,体现了多模态技术在实际应用中的广泛潜力和影响力。
开篇
OpenAI最近在其平台上宣布了一系列引人注目的新增和改进功能,这些更新旨在进一步推动人工智能的边界扩展。这些更新不仅包括了性能更强大且成本更低的新型GPT-4 Turbo模型,而且还引入了多模态能力,这将极大地扩展开发者和研究人员的创新空间。以下是这些更新的要点:
1.GPT-4 Turbo模型:这个新模型代表了大规模语言模型的最新进展。它不仅性能更强大,而且价格更亲民。这一模型支持高达128K的上下文窗口,意味着可以处理更长的对话和文本。GPT-4 Turbo的出现,显著提升了开发者利用大型语言模型潜能的能力,让模型成为了一个真正的“全才”。
2.多模态功能:在多模态领域的最新进展尤为引人注目。OpenAI平台上的新功能包括了视觉能力的提升、图像创造(DALL·E 3)以及文本到语音(TTS)技术。这些多模态功能的结合不仅开启了新的应用场景,还为用户提供了一个更加丰富和互动的体验。
3.助手API(Assistants API):OpenAI新推出的助手API让开发者更加便捷地构建目标明确的AI应用。这个API提供了调用模型和工具的简化方式,从而使开发复杂的辅助性AI应用成为可能,无论是为了业务流程自动化,还是为了增强用户体验。
看到这些功能的加入,让人热血澎湃,我迫不及待地登陆GPT尝鲜这些功能。特别是多模态的功能让我印象深刻,这里我将实践操作以及代码的分析与大家做一个分享。
多模态初探
多模态技术是一个日益流行的领域,它结合了不同类型的数据输入和输出,如文本、声音、图像和视频,以创造更丰富、更直观的用户体验。以下是多模态技术的几个关键方面:
1.综合多种感知模式:多模态技术整合了视觉(图像、视频)、听觉(语音、音频)、触觉等多种感知模式。这种集成使得AI系统能够更好地理解和解释复杂的环境和情境。
2.增强的用户交互:通过结合文本、图像和声音,多模态技术提供了更自然、更直观的用户交互方式。例如,用户可以通过语音命令询问问题,同时接收图像和文本形式的答案。
3.上下文感知能力:多模态系统能够分析和理解不同类型数据之间的关系,从而提供更准确的信息和响应。例如,在处理自然语言查询时,系统能够考虑相关的图像或视频内容,从而提供更为丰富的回答。
4.创新应用:多模态技术的应用范围广泛,包括但不限于自动化客服、智能助手、内容创作、教育、医疗和零售等领域。它允许创建新型的应用程序,这些应用程序能够更好地理解和响应用户的需求。
5.技术挑战:虽然多模态技术提供了巨大的潜力,但它也带来了诸如数据融合、处理不同数据类型的复杂性以及确保准确性和效率的挑战。
6. OpenAI的多模态实例:在OpenAI的框架下,多模态功能的一个显著例子是DALL·E 3,它是一个先进的图像生成模型,可以根据文本描述创建详细和创造性的图像。此外,文本到语音(TTS)技术则将文本转换为自然 sounding的语音,进一步丰富了人机交互的可能性。
多模态原理解析
前面我们对多模态进行了基本的描述,多模态是指能够理解和处理多种类型数据(如文本、图像、声音等)的技术。实现文本-图片-声音-视频之间的转换。转化是表象,实质需要理解。
在人工智能领域,多模态方法通常结合了自然语言处理(NLP)、计算机视觉(CV)和其他信号处理技术,以实现更全面的数据理解和处理能力。
为了说明多模态的工作原理,我们这里举一个从文字转图片的例子,帮助大家理解。我们将整个过程展示如下:
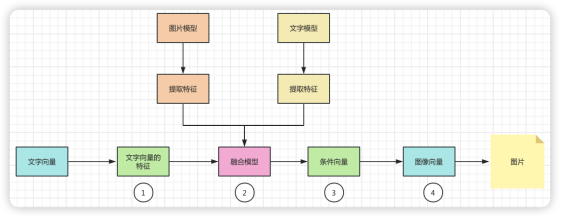
1. 文本特征提取:
首先,文本输入通过一个文本模型(例如一个预训练的语言模型)来提取文本特征。这个过程涉及将文本转换成一个高维空间的向量,这个向量能够表示文本的语义内容。
2. 融合模型:
在某些情况下,确实会存在一个专门的融合模型,它是在训练阶段通过学习如何结合不同模态的数据而得到的。这个融合模型将在推理阶段使用。
在其他情况下,融合模型可能是隐含的。例如,在条件生成模型中,文本特征向量直接用作生成图像的条件,而不需要显式的融合步骤。
3.条件生成:
融合模型(或者直接从文本模型得到的特征向量)用于为图像生成模型设定条件。这个条件可以理解为指导生成模型“理解”文本内容,并据此生成匹配的图像。
4.图像生成:
最后,图像生成模型(如DALL·E或其他基于生成对抗网络的模型)接收这个条件向量,并生成与之相匹配的图像。这个过程通常涉及到大量的内部计算,模型会尝试生成与条件最匹配的图像输出。
整个流程可以简化为:文本输入 → 文本特征提取 → 特征融合(如果有)→ 条件生成 → 图像输出。在这个过程中,“融合模型”可能是一个独立的模型,也可能是条件生成模型的一部分。关键点是,推理时的特征融合是基于在训练阶段学到的知识和参数进行的。
多模型体验
了解了多模型实现原理之后,我们来登陆ChatGPT体验一下,现在在ChatGPT4中已经集成了DALLE 3 的功能,我们只需要输入指令就可以生成对应的图片。如下所示,我们通过文字描述一只可爱的猫咪,ChatGPT 就能够帮我完成图片的生成。
不止于此,OpenAI还能够识别图片,当你提供图片之后,OpenAI会根据图片描述其中的内容,如下图我们从网络上找到一张小猫的图片,丢给OpenAI让它识别一下。

这次我们通过调用OpenAI的API,来实现上述功能。毕竟作为程序员不敲敲代码,只是用工具输入文字还是不太过瘾。
这段代码使用 Python 和 OpenAI 库来与 OpenAI 的 GPT-4 API 交互。目的是创建一个聊天会话,其中用户可以向模型发送图像地址。代码通过URL地址,读取图像并且对其进行识别,最终输出理解的文字。
import os
import openai
# 导入所需库:os 用于读取环境变量,openai 用于与 OpenAI API 交互。
openai.api_key = os.getenv('OPENAI_API_KEY')
# 从环境变量获取 OpenAI 的 API 密钥并设置。这样可以避免将密钥硬编码在代码中,提高安全性。
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
# 指定使用的 GPT-4 模型版本。这里用的 'gpt-4-vision-preview' 表示一个特别的版本,可能包含处理图像的能力。
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这张图片表达了什么意思?"},
{
"type": "image_url",
# 用户消息 (messages),包括一段文本和一个图像的 URL
"image_url": "http://www.jituwang.com/uploads/allimg/160327/257860-16032H3362484.jpg"
},
],
}
],
# 响应的最大长度 (max_tokens)
max_tokens=200,
)
print(response.choices[0])分享说明:转发分享请注明出处。



