





本文经自动驾驶之心公众号授权转载,转载请联系出处。
实时局部建图领域自从端到端方案MapTR(2023.1)[1]问世后已经又涌现出非常多优秀的工作,基本是在MapTR基本框架的基础上进行一系列改进,包括原班人马的升级作品MapTRv2(2023.8)[2].博主准备从MapTRv2开始至今(2024.5)发表的比较优秀的论文按时间顺序做一个梳理,大概18篇,因为数量较多不具体介绍每个模块,只按自己的理解概括最核心的创新点,在文章结尾会对18篇论文做一个简要总结,希望对从事相关领域研究的同学和业内人士有所帮助.
[1] MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction
[2]MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction
1.BeMapNet(2023.6][3]
[3] End-to-End Vectorized HD-map Construction with Piecewise Bezier Curve
BeMapNet是在MapTR之后发表的,但没有借鉴MapTR架构,而是在基于图像分割+复杂后处理得到向量化地图元素的模型,如HDMapNet[4] 的基础上,首次提出使用分段的贝塞尔曲线来表征地图元素,实现端到端的目的.关于贝塞尔曲线可参考这篇博客:启思:从零开始学图形学:10分钟看懂贝塞尔曲线(https://zhuanlan.zhihu.com/p/344934774).
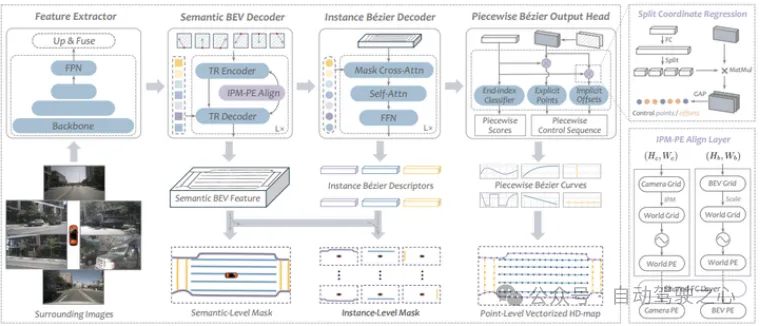
BeMapNet架构
为了能更加准确且高效地表示形状复杂多变的地图元素,论文中使用分段的贝塞尔曲线,并且使用固定的阶数和可变的分段数.由Bezier Decoder输出实例级的贝塞尔曲线特征,再由Piecewise Bezier Output Head输出point级的贝塞尔曲线控制点序列.文中还使用IPM-PE Align Layer为bev feature提供IPM投影的几何先验信息.
2.MapTRv2(2023.8)[2]
是MapTR的提升版,文中总结的第一个创新点是置换等价(permutation-equivalent)建模方法,也就是对gt建立多个按不同顺序排列的点集副本,目的是消除排列顺序的影响,然后用分层二分匹配(Hierarchical bipartite matching)的方式与query的预测结果做匹配,匹配的标准是与距离最近的一种排列的gt的距离,有点绕,因为在原版MapTR已经用到,不过多介绍.
第二个创新点是MapTRv2的核心,是对decoder的self-attention和cross-attention都做出了改进.对self-attention的改进是使用分层query embedding的方案代替之前的全量query embedding,就是建立实例级的instance query 和关键点级的point query两个集合,分别在集合内部做self-attention,再用广播相加的方式代表全量的query集合,这种共享权重的方式不仅能为每个point赋予对应的instance信息,还能极大地减少计算量,在精度和性能上都有很大提升.对cross-attention的改进主要是混合了BEV-based和PV-based cross-attention,充分利用BEV和PV信息.下图可以直观展示这种设计:
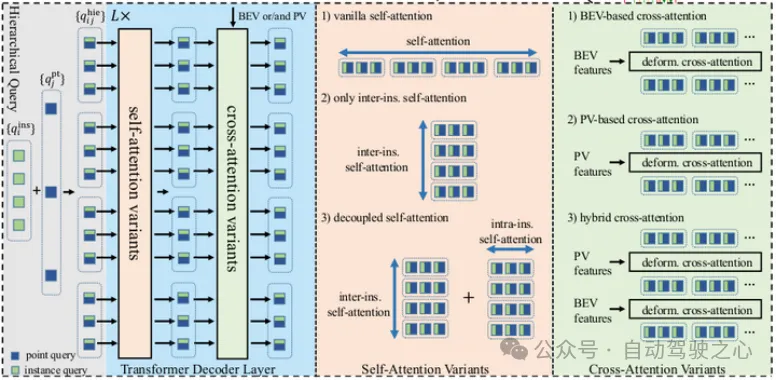
MapTRv2 的Map decoder结构
还有一个创新是结合了one-to-one和one-to-many匹配.one-to-one自不必说,one-to-many是另外设计了一组instance query,与复制了K次的gt进行匹配,这样可以增加正样本的匹配成功概率,加快模型的收敛.
3.StreamMapNet(2023.8)[4]
[4]StreamMapNet: Streaming Mapping Network for Vectorized Online HD Map Construction
StreamMapNet主要在时序方面对MapTR进行了提升.核心策略是近期出现的streaming strategy,在去年发布的VideoBEV [5],StreamPETR [6], Sparse4D v2 [7]等论文都有应用,不同于传统的单iteration迭代多帧或者stacking多帧的方式,streaming strategy单iteration只迭代一帧,在iteration之间做时序融合,可以实现时序模型的训练时长与单帧模型相当,且能融合长时序数据,大幅提升了训练效率.在StreamMapNet的时序融合中,使用了稠密bev feature和稀疏query同时融合的方式,bev feature采用Gated Recurrent Unit [8] (GRU)模块进行融合,稀疏query采用和Sparse4D v2类似的方式,按置信度取top k个query迭代到下一帧,与下一帧新初始化的query进行合并,再用一个transformation loss进行约束.
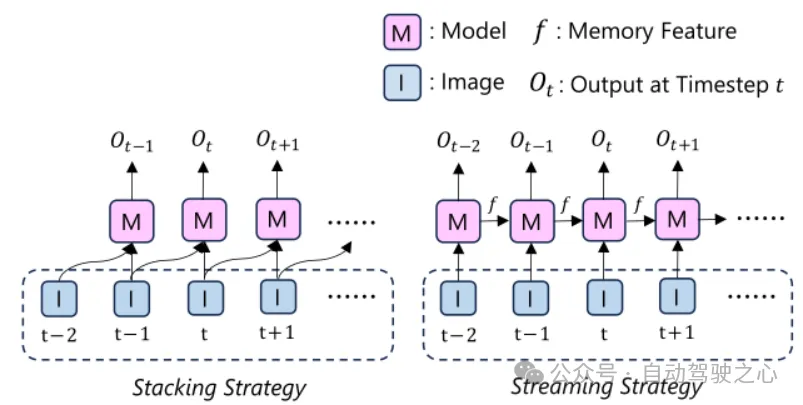
Stacking 和 Streaming 策略对比
[5]Exploring recurrent long-term temporal fusion for multi-view 3d perception
[6] Exploring object-centric temporal modeling for efficient multi-view 3d object detection
[7] Sparse4d v2: Recurrent temporal fusion with sparse model
[8] Empirical evaluation of gated recurrent neural networks on sequence modeling
文中还使用了Multi-Point Attention代替原始deformable DETR的cross-attention设计,参照MapTRv2, 本质上是只使用了instance query,没有point query,一个instance query负责预测多个点,生成多个reference points,而不是原始deformable DETR中一个query预测一个点,生成一个reference points,加多个offset.这样是为了适应地图元素的non-local特性.我认为本质上与区分instance query和point query差不多.
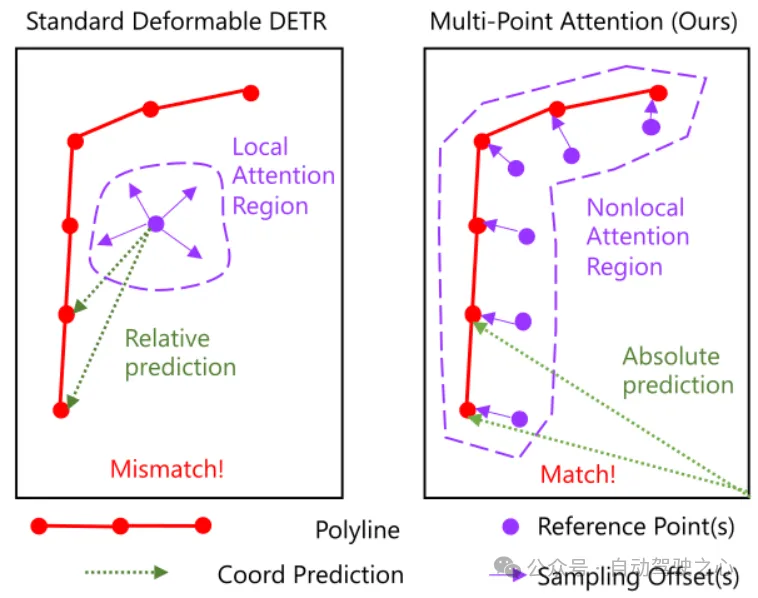
Multi-Point Attention
4. InsightMapper(2023.8)[9]
[9] InsightMapper: A closer look at inner-instance information for vectorized high-definition mapping
InsightMapper也是在MapTR基础上做出一些改进.第一是细化了地图元素预处理,如下图所示,将原Polyline的复杂形状都在交点切分成多个简单形状,降低模型学习难度.
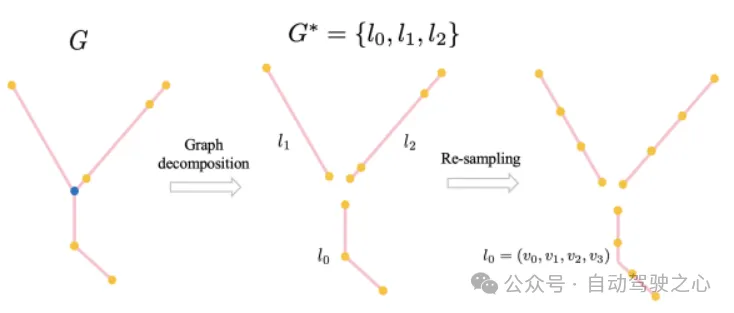
地图元素预处理
第二是提出MapTR的分层query embedding的设计有一个问题是instance之间共享了point query的权重,导致不同instance的points错误地有了一定的关联性.所以文中没有设定共享point query权重,而是对每个instance设置不同的point query,称为Hybrid query, 消除这种错误的关联.在做self-attention进行instance内部信息交互的时候设计一个attention-mask,让属于不同的instance的point query之间不可见,只在instance内部进行交互.
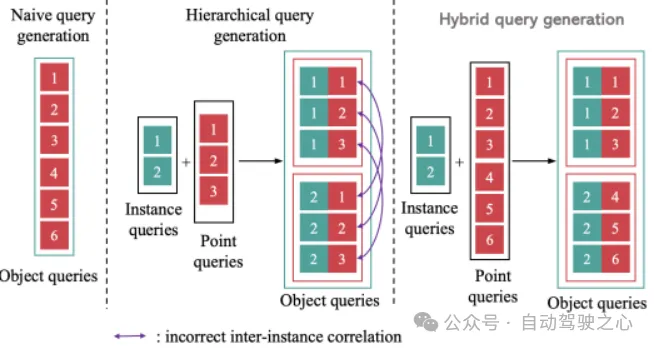
Hierarchical query和Hybrid query对比
5. MapPrior(2023.8)[10]
[10] MapPrior: Bird's-Eye View Map Layout Estimation with Generative Models
MapPrior是一种结合感知和先验的地图模型,先验用的是预训练生成模型,整体结构如下:因为对生成模型了解不是很深,就不具体介绍了.
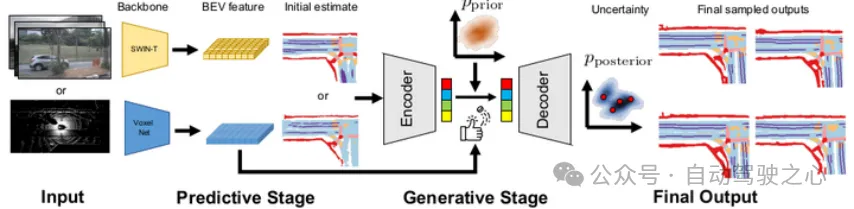
MapPrior架构
6.PivotNet(2023.9)[11]
[11] PivotNet: Vectorized Pivot Learning for End-to-end HD Map Construction.
PivotNet针对MapTR使用固定数量且地位一致的点表征复杂地图元素会引起形状信息损失的问题,提出了用关键点(pivot)和共线点(collinear point)表征地图元素的端到端框架.关键点即对元素形状产生决定性影响的点,如下图所示.
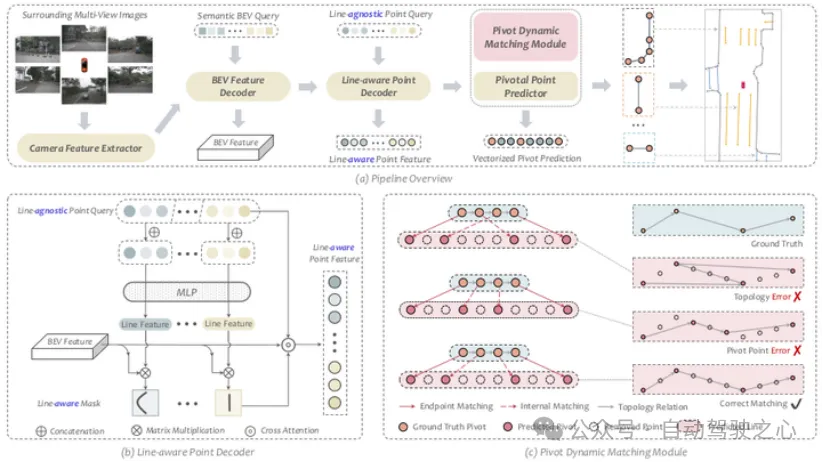
Pivotnet架构
首先在query的设定上并没有采用分级的架构,而是只有point query,在Line-aware Point Decoder模块中,由最多N个point query concate起来经过MLP得到Line feature,再与BEV feature相乘得到一个可学习的Line-aware mask,通过与BEV 语义分割的真值做bce loss和dice loss进行约束,得到query与instance的关系.
最关键的部分在于关键点预测和匹配模块,不同于MapTR同样数量的dt和gt做一对一匹配,这里先计算出一个实例的gt的T个关键点,T是动态变化的,然后在N个dt里找到最优的T个组合,即为dt的关键点,剩下即为共线点,都是带有顺序的.为了提高效率,文中还使用了一些优化措施.匹配结束后,利用对关键点和共线点不同的约束条件进行约束.实验证明Pivotnet比起MapTR能够更好地预测元素的形状和角度.
7.MapVR(2023.10)[12]
[12] Online Map Vectorization for Autonomous Driving: A Rasterization Perspective
MapVR(Map Vectorization via Rasterization)通过一个额外的可微栅格化模块来学习更好的向量化地图,架构如下:
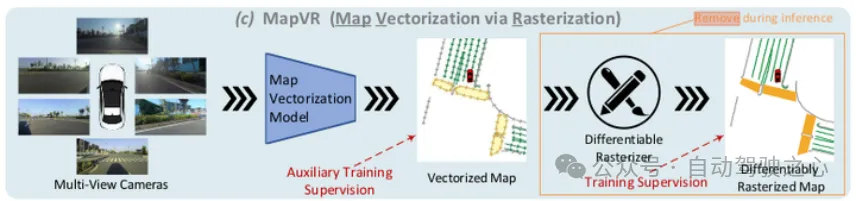
MapVR架构
文中提出,类似MapTR的向量化地图模型的问题是使用Chamfer distance做gt和dt的匹配存在两个缺陷,一是没有尺度不变性,即对于大尺度和小尺度地图元素采用一样的标准不合理,二是这种方式忽略了形状和几何特性,会得出不合理的结果,图示如下:
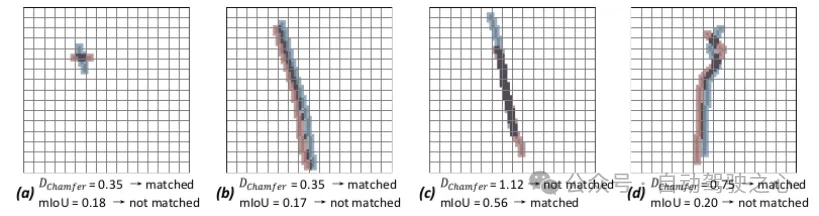
Chamfer Distance匹配的问题
而如果使用栅格化地图,就可以以mIOU为标准,匹配更加准确,如下图所示:
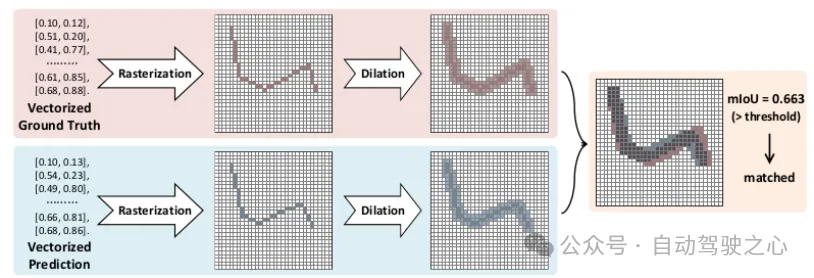
mIOU匹配
文中首次使用近期相关研究中提出的一种无参数的可微分的栅格化[11]来作为向量化地图和栅格化地图的桥梁.在训练阶段可以更准确地实现gt和dt的匹配,使loss计算更加准确,帮助模型收敛,在推理阶段可以移除这个模块,输出更好的向量化地图.
[13] Soft rasterizer: A differentiable renderer for image-based 3d reasoning
8.MapEX(2023.11)[14]
[14] Mind the map! Accounting for existing map information when estimating online HDMaps from sensor data
在实际工程应用中,往往还不能完全抛弃传统高精地图,但传统高精地图有着生成周期长,更新慢的缺点,MapEX就是利用已有的未更新的先验地图数据,结合传感器实时感知,给出一个实时的地图结果,是一个非常有实际工程价值的模型,比起只使用传感器输入有质的提升.
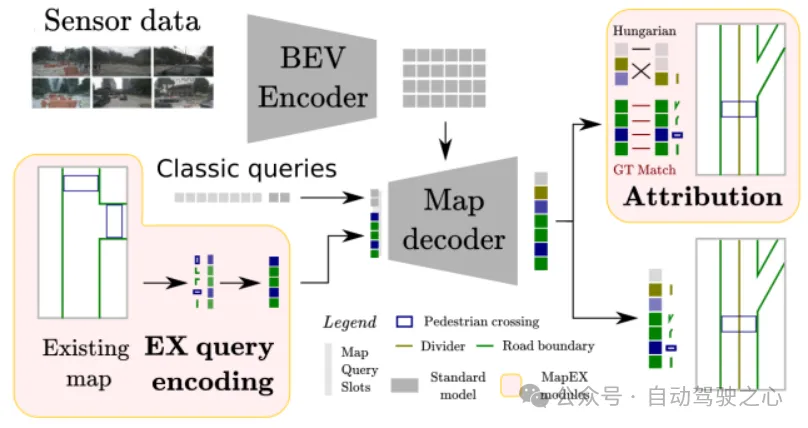
MapEX架构
如果是在工程中存在发生变化的真实地图数据,那可以直接作为输入的EX-GT(Existing map GT),如果使用开源数据集不存在发生变化的场景,文中做了一些场景模拟,来模拟地图的变化,如元素缺失,元素加噪,元素彻底变化等等,随机对GT做一些处理后作为输入的EX-GT.

MapEX的模拟场景
MapEX的框架也是建立在MapTR框架的基础上,将decoder原来使用的初始化query的一部分替换为从EX-GT的位置和类别编码而来的EX-query,编码的方式如下图所示:
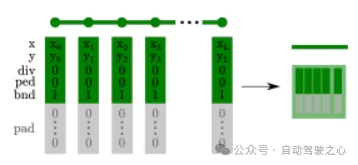
Ex query编码
然后在匹配过程中并不是直接使用匈牙利匹配,而是对EX-query做一个预匹配,即对与真实GT实例的所有点的平均距离小于1m的EX-query直接匹配为对应的GT,剩下的query再进行匈牙利匹配,降低模型学习的难度.这样就可以充分利用已有地图数据的先验信息,得到更加准确的实时输出.
另外MapEX还有一个地图变化检测模块,即使用一个独立的change detection query,与decoder每一层的全部query做cross-attention,融合所有query的信息,最后回归出地图变化的置信度.
9.GeMap(2023.12)[15]
[15] Online Vectorized HD Map Construction using Geometry
GeMap也是利用几何先验对地图元素进行约束的模型.对比BeMapnet,PivotNet等模型,大多基于绝对坐标,不具备旋转平移不变性,且没有考虑到实例之间的相关性,如车道线之间一般平行,且距离与车道宽度有关,车道线与路口一般垂直等.GeMap基于实例的位移矢量(displacement vectors),从它自身的形状线索和不同位移矢量之间的相关性线索对输出实例和点集进行约束,能够更加准确地利用地图元素的几何特征.
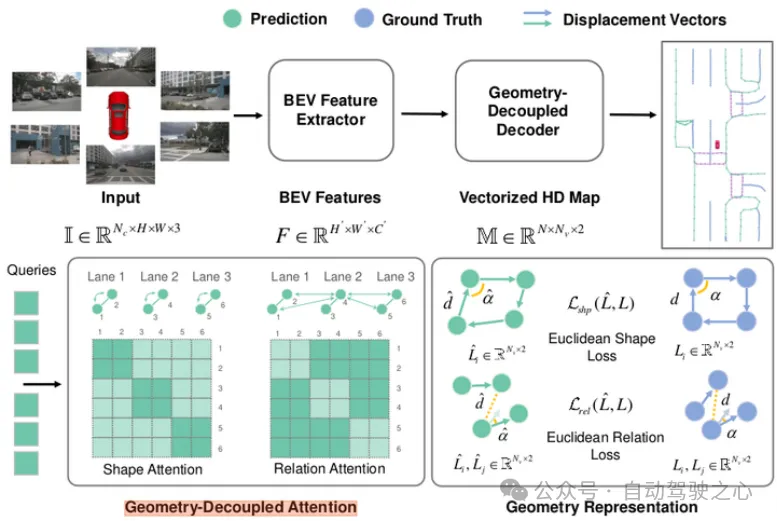
GEMap框架
具体是通过Geometry-Decoupled Attention和Euclidean loss实现的.前者设计了两个解耦的attention模块,通过不同的attention-mask,一个关注于实例内部的形状信息,一个关注于实例之间的相关性信息.后者是分别对形状和相关性进行约束,公式如下(实际操作中使用了优化效率的策略),另外也使用了segmentation, depth, dorection 和pts loss.
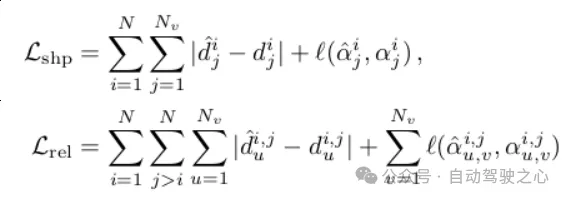
Euclidean Loss
10. ScalableMap(2024.1)[16]
[16] ScalableMap: Scalable Map Learning for OnlineLong-Range Vectorized HD Map Construction ScalableMap
ScalableMap使用一种类似于缩放的方式来更好地还原出地图元素的结构化信息,实现长距离场景的性能提升,在整个架构上都做出了一些改进.
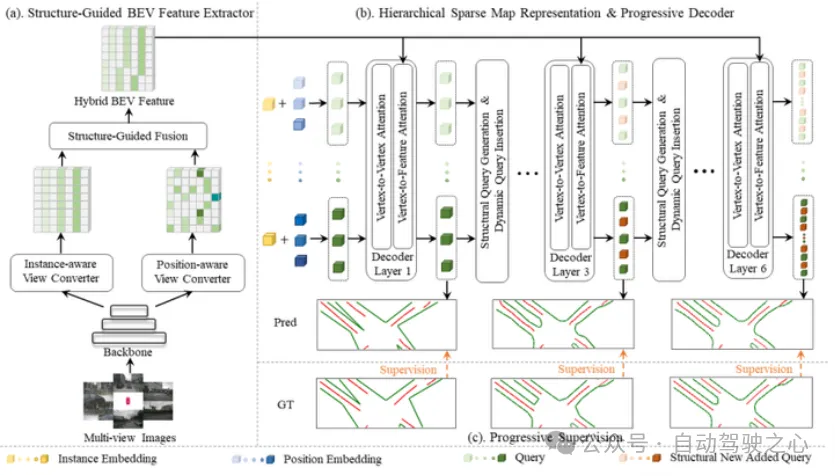
ScalableMap架构
首先是BEV特征提取部分,第一步是分为两个分支,一个通过DETR架构得到类似BEVFormer的position-aware的全局BEV特征, 另一个利用MLP得到的基于每个视角的instance-aware的k个BEV特征,多视角BEV特征再通过线性层融合成为统一的BEV特征.第二步是两个BEV特征经过Structure-Guided 特征融合模块,并加入一个额外的分割头,对两个BEV特征分别进行矫正和融合,使其同时具备准确的位置和形状信息.
其次是使用渐进的Decoder来实现多尺度的地图表示和监督,核心是HSMR策略,即定义地图密度为地图元素中曲率超过阈值的顶点数量, 获得渐进的不同密度的地图元素表示.在gt中,对顶点过多的元素进行采样,对顶点较少的元素进行插值,可以获得不同密度的gt; 在Decoder每层的query设定中,采用动态插入的方法,即利用相邻顶点之间的位置约束生成新的query,动态地插入到原始query序列中,以此获得不同密度的query序列.
在loss约束上也使用渐进的loss约束,一是Vertex loss, 分别对原始顶点和新加入的顶点进行约束,前者使用L1 loss,后者使用顶点到所属边的距离,二是Edge Loss对形状进行约束.
11.mapNeXt(2024.1)[17]
[17] MapNeXt: Revisiting Training and Scaling Practices for Online Vectorized HD Map Construction
mapNeXt是从实际工程的角度对mapTR进行优化.首先通过分析mapTR对gt的置换等价处理,即对每个gt增加所有可能的排列再进行匈牙利匹配,发现如果使用无序的Chamfer Distance作为距离代价,可以忽略置换等价带来的影响.作者通过增加decoder中query的组数,采用并行的方式进行一对一的匈牙利匹配,得到了较好的效果,且不影响推理效率.另外没有采用隐式的位置编码,而使用显式的无参数的sin位置编码提供位置先验可以提升效率.
在模型迁移和缩放方面,分析了各种预训练模型的性能,由于decoder增加了更多的query,选择使用更强的VoVNetV2 backbone+FFN并做了规模扩展的适配,而且在使用PETRv2的nuScenes BEV地图分割任务上预训练,实现更好的模型迁移.
12.Stream Query Denoising(SQD)(2024.1)[18]
[18] Stream Query Denoising for Vectorized HD Map Construction
Stream Qurty Denoising(SQD)是在StreamMapNet[4]的基础上进一步结合了去噪的思想,帮助模型更好的收敛.去噪的思想由DN-DETR[19]等一系列论文启发,是通过对gt加噪声构建denoise query,直接绑定对应的gt而不需要匈牙利匹配,使transformer减少被匈牙利匹配不稳定的特性所影响,实现更快的收敛.
[19] Dn-detr: Accelerate detr training by introducing query denoising.
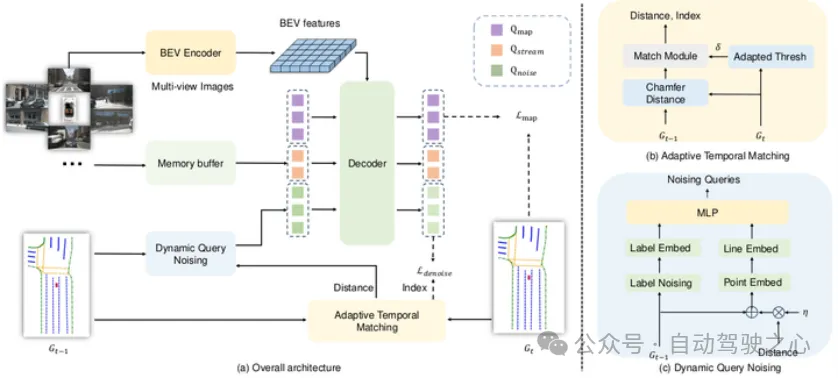
SQD架构
SQD整个架构与StreamMapNet类似,通过stream的方式实现时序融合,包括bev feature的融合和top k query的融合,这里前序帧query对应的gt,以及前序帧的bev feature都根据ego-motion进行了转换.
SQD核心改进在于Denoising模块,和DN-DETR不同的是SQD是对前序帧的gt进行加噪.首先针对curve的特性,采取和bbox不同的加噪方式: line shifting, angular rotation, 和scale transformation,再编码成位置嵌入,构造noise query,和当前帧的query以及前序帧的top k query进行拼接,一起输入decoder.
进一步地,文中考虑到前一帧gt转换到当前帧后可能带来的偏差,如新增,缺失,位置偏差等,设计了Adaptive Temporal Matching和Dynamic Query Noising模块作为补充和增强.前者计算了前序帧经过时序转换以后和当前帧的Chamfer Distance,只把小于阈值的gt用来与当前帧的query做匹配.后者在对前序帧加噪的过程中设计了decay rate,结合实例的变化尺度进行有针对性的加噪.
13.ADMap(2024.1)[20]
[20] ADMap: Anti-disturbance framework for reconstructing online vectorized HD
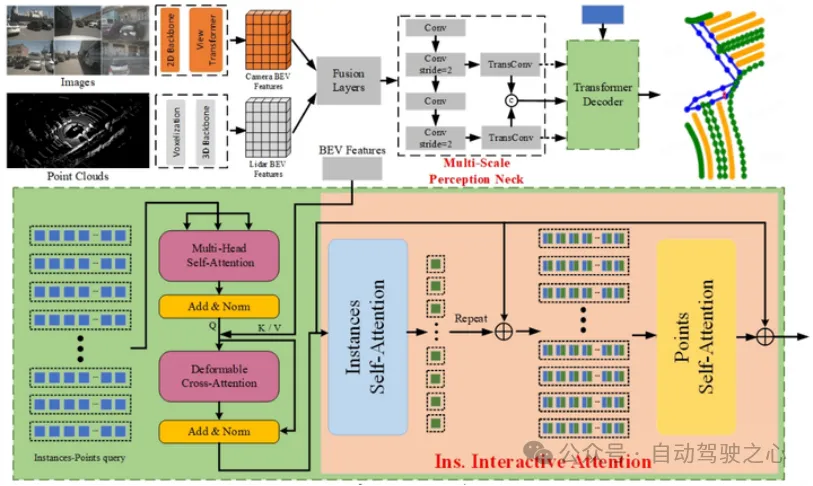
ADMap架构
ADMap提出由于MapTR预测的点会发生抖动和移位,导致预测的实例会变得扭曲和锯齿状.为了提高模型的抗干扰能力,在MapTR的基础上对网络和Loss做出一些改进,主要有三个部分:Multi-Scale Perception Neck (MPN), Instance Interactive Attention (IIA) and Vector Direction Difference Loss(VDDL).
MPN类似于FPN,将bev feature通过下采样和上采样得到不同尺度的bev 特征,便于decoder能得到多尺度的信息.
IIA首先在分级query(instance query 和point query)设计的基础上,改变了MapTR中instance query的生成方式:通过point query的维度转换和多层MLP学习而来,先经过Instance-self-attention进行实例之间的信息交互,再与point query相加,经过Points-self-attention学习实例内部的点之间的信息交互.
VDDL则设计了带权重的向量方向损失,来进一步约束实例向量的形状和方向.方向损失由逐点与gt的夹角余弦获得,权重取决于gt的方向变化,即对方向变化剧烈的实例给予更大的权重.
14.MapQR(2024.2)[21]
MapQR致力于在MapTR的基础上进一步挖掘查询机制(query)的潜力,只使用instance query,共享同一地图中的内容信息,避免使用points query发生同一地图元素的信息不一致性,同时可以减少计算量.
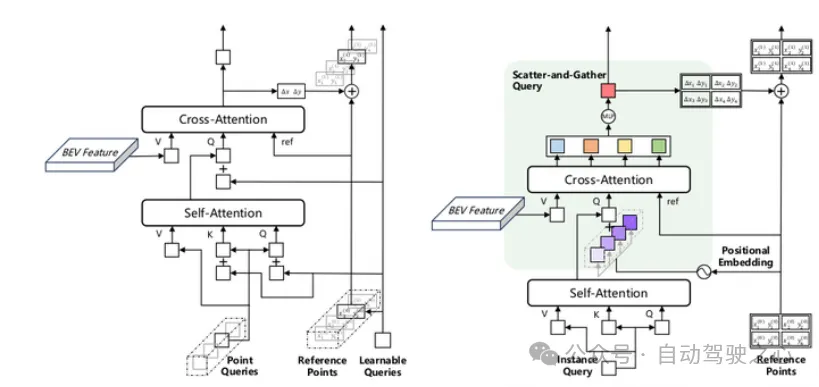
MapTR和MapQR的Decoder对比
作者称这种实例查询机制为Scatter-and-Gather Query,首先定义N个Instance query,经过self-attention后通过Scatter操作每个扩展为n个副本,根据不同的n个reference points生成不同的Positional Embedding,再concate后输入cross-attention,最后将输出的query通过Gather操作恢复为instance query,每个query负责预测n个点.另外,在reference points的设计上,MapQR考虑了不同高度的影响.
15.EAN-MapNet(2024.2)[22]
[22] EAN-MapNet: Efficient Vectorized HD Map Construction with Anchor Neighborhoods
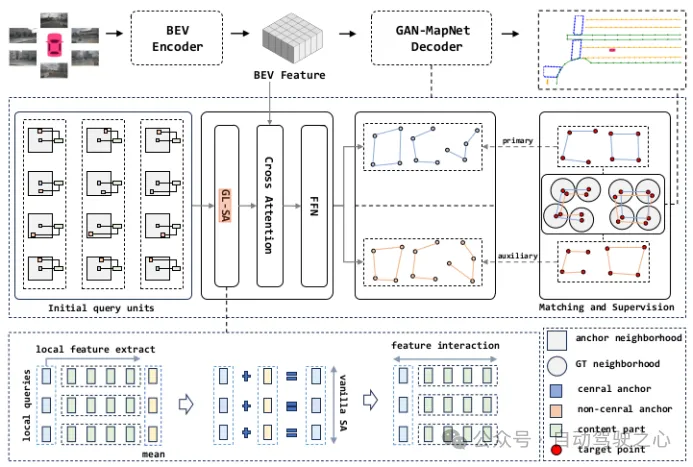
EAN-MapNet架构
EAN-MapNet提出,建图模型一般使用DETR decoder,这种query构建机制缺少对地图元素临近的局部位置特征的关注,所以参照anchor思想,在BEV空间初始化多组anchors,每个anchor设计了查询单元(query units)机制,由neighborhood central query和non-neighborhood central query构成,同样GT除了target points, 也在半径为r的区域增加gt neighborhoods,neighborhood central query与target points相匹配,non-neighborhood central query与gt neighborhoods中的随机点相匹配.
文中还设计了Grouped local self-attention(GL-SA)模块适应这种query机制,分为局部特征提取,组间特征交互,组内特征交互三步,以更好地利用局部特征.损失函数方面也同时考虑了center和none-center区域的损失.
16.HIMap(2024.3)[23]
[23] HIMap: HybrId Representation Learning for End-to-end Vectorized HD Map Construction
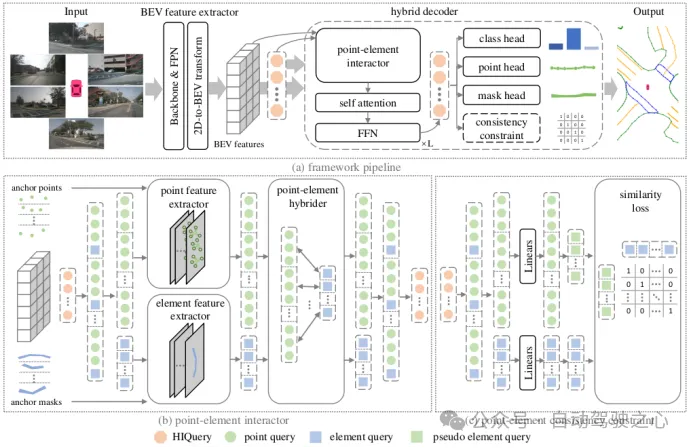
HIMap架构
HIMAP也是在query机制和decoder设计上对MapTR进行改进,使模型能够更好地学到实例级的特征.首先设计了混合的HIQuery,包含E个element query和E* P个point query,再把两种query分别输入element特征提取器(参照Masked Attention[24])和point特征提取器(参照DAB-DETR[25]),point query属于一个实例的positional embedding的加权和作为element query的positional embedding.更新好的point query和elementquery会输入point-element hybrider进行信息融合,具体方式是属于同一个实例的point query会与对应的element query相加,然后每个element query会与对应的所有point query的加权和相加,这样point query 和element query都同时拥有了点的信息和实例信息,再作为新的HIMAP输入下一层decoder.
[24] Masked-attention mask transformer for universal image segmentation.
[25] Dab-detr: Dynamic anchor boxes are better queries for detr.
为了保证point query和element query的一致性,作者做了一致性约束,即计算point query的加权和与对应的element query的交叉熵加到总loss中.
17.MapTracker(2024.3)[26]
[26] MapTracker: Tracking with Strided Memory Fusion for Consistent Vector HD Mapping
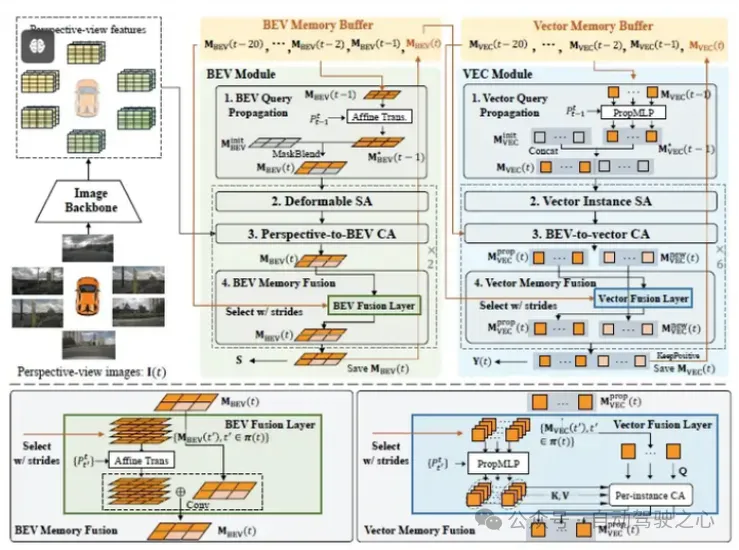
MapTracker架构
MapTracker是用跟踪的方式更好地进行时序增强,从而使建图更加准确和一致性,鲁棒记忆机制是核心.文中借鉴MOTR[27]的端到端目标跟踪思想,一共用到两种记忆机制,一是BEV feature的记忆,会从前面10帧中选取更接近1m/5m/10m/15m的4帧,经过ego-motion转换后用两层卷积层融合.二是Vector记忆,每帧由100个新初始化的vector和若干历史帧保存的预测score超过阈值的positive vector经过时空变换和MLP拼接而成,对应于同一个地图元素的历史vector会被融合.
[27] MOTR: End-to-End Multiple-Object Tracking with Transformer
训练过程中同时考虑BEV loss,VEC loss和Transformation loss,同时对BEV特征,地图元素匹配和跟踪,时序融合的一致性进行约束.采用增强每帧的几何特性,前后两帧之间建立匹配关联的方式提高gt的一致性,并采用带有一致性信息的mAP做为评测标准.文中没有具体说推理机制,应该与训练机制一致.
18.P-MapNet(2024.3)[28]
[28] P-MapNet: Far-seeing Map Generator Enhanced by both SDMap and HDMap Priors
P-MapNet是除MapEX[14]外另一种结合已有地图先验来辅助当前建图的方式,与MapEX采用直接替换query不同,P-MapNet主要使用cross-attention和MAE[29] finetune的方式来融合二者信息.
[29] Masked autoencoders are scalable vision learners.
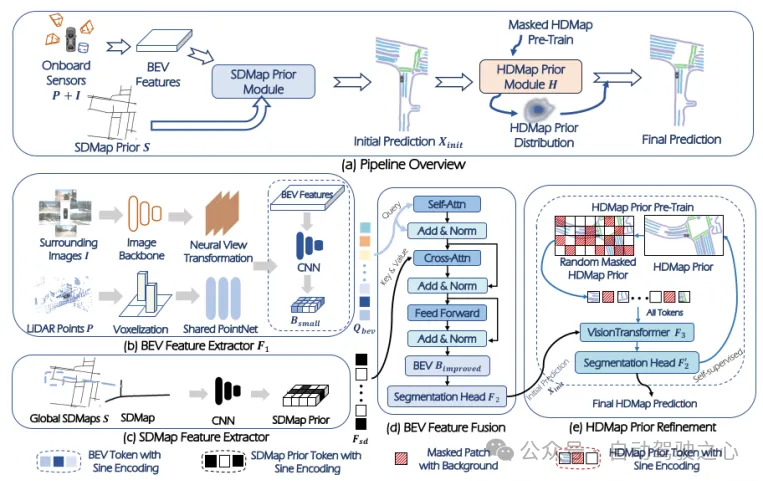
P-MapNet架构
文中同时利用了比较粗的SDMap和比较精细的HDMap先验进行信息融合.首先是SDMap融合模块.SDMap信息可以从GPS获取,经过CNN网络得到SDMap特征,与传感器(包括camera/lidar)融合和视角转换得到的BEV feature(经过下采样)通过cross attention进行融合,再接一个segmentation head得到一个较粗的分割地图.
然后是HDMap融合模块.这里首先有一个MAE预训练步骤,与原生的MAE不同,这里的预训练是输入带有mask的栅格地图原始image,再通过一个segmentation head输出语义分割地图,与原生MAE的作用相同,都是作为一个具有较强恢复能力的autoencoder,结构大体是VIT+segmentation head.预训练结束后,将SDMap和传感器融合的segmentaion结果输入MAE,得到refine的segmention结果.
看到这大家可能有点confused, 最后对上面18个模型做个简短的总结:
使用地图元素的几何特性进行约束: BeMapNet, PivotNet, GeMap, ADMap
对MapTR 的query机制进行改进: MapTRv2, StreamMapNet, InsightMapper, ADMap, MapQR, EAN-MapNet, HIMap
时序优化: StreamMapNet, SQD(加去噪), MapTracker(跟踪)
使用先验信息: MapPrior, MapEX, P-MapNet
其他: MapVR(栅格化辅助), mapNeXt(工程优化)



