





作者 | Thought Agent 社区
在对话系统的设计和实现中,传统的基于 Rasa-like 框架的方法往往需要依赖于多个模块的紧密协作,例如我们在之前的文章中提到的基于大模型(LLM)构建的任务型对话 Agent,Thought Agent,其由自然语言理解(NLU)、对话管理(DM)和对话策略(DP)等模块共同协作组成。这种模块化的设计虽然在理论上具有灵活性,但在实践中却带来了诸多挑战,尤其是在系统集成、错误传播、维护更新以及开发门槛等方面。

为了克服这些挑战,构建一个端到端(E2E)的模型显得尤为关键。E2E 的模型通过将对话的各个阶段集成到一个统一的框架中,极大地简化了系统架构,提高了处理效率,并减少了错误传递的可能性。此外,由于其简化的架构,也更易于维护和更新,从而降低了开发和维护的成本。
在我们看来,端到端的对话 Agent 不仅在技术上更具优势,而且在实际应用中也展现了其独特的价值和潜力,例如能够快速构建帮助用户查询信息、调度技能的 Agent。
本文将指导读者如何采用蒙特卡洛方法(Monte Carlo)模拟用户行为并结合 LLM 的方法来构建训练数据集;使用 LLaMA Factory 对多种 LLM 进行高效微调构建任务型对话 Agent。该方案允许用户快速创建出能够精准调用外部工具的 Agent。
挑战
任务型对话系统的核心需求包括意图识别、槽位填充、状态管理和策略决策。我们识别了以下几个关键挑战:
- 微调后的 LLM 需要从用户的问题中识别到用户意图和关键信息(槽位)
- 微调后的 LLM 需要对用户的问题有判断边界的能力,容易混淆的内容将触发意图确认,完全无关的内容将触发兜底话术
- 微调后的 LLM 需要根据槽位填充状态判断合适的触发功能调用(Function calling)的时机
- 微调后的 LLM 需要对根据上下文正确的识别到需要用于调用功能的关键信息
构造数据集
为了应对上述挑战,首先我们需要构造能够覆盖大部分场景的对话数据集,我们面临的核心难点是如何模拟真实世界中用户的多样化行为和对话系统的有效响应。但是对于任务型对话 Agent 来说,用户和 Agent 之间的对话域是有限的,因为 Agent 只需要处理业务范围内的用户意图,超出处理范围的内容,只需要返回一些固定的兜底话术即可。
因此我们可以采用了状态图对对话的过程进行建模,使用蒙特卡洛方法对真实的对话过程进行模拟,接着使用 LLM 的生成能力来创建符合状态、角色定义的对话内容从而达到构建数据集的目的。
1.基于图的对话流程图的建模
我们使用有向图(Directed Graph)的数据结构来对通用的任务型对话流程进行建模,这比传统的有限状态机更加灵活和通用。在构建对话流程图时,我们首先定义了一组节点,每个节点代表了对话中的一个关键状态。例如,一个理想的对话过程至少包含以下节点:
- Start: 对话开始
- IntentAcquire: Agent 询问用户意图
- UserInquiry: 用户发起新的提问
- IntentConfirm: Agent 向用户确认意图 (用户意图不明确时)
- UserConfirm: 用户确认意图
- UserDeny: 用户否认意图
- AskSlot: 追问用户关于该意图的关键信息(槽位)
- ProvideSlot: 用户提供或更新关键信息
- FunctionCalling: 调用功能,传递槽位信息
- Chitchat: 用户闲聊
- End: 对话结束
在定义了节点之后,我们使用边将可以进行状态转移的节点连接起来,从而构建一个有向图用来表征对话过程中所有可能的转移关系,如下图。在这个图中,主要的变量是用户对话内容,Agent 的回复内容是随着用户的对话意图和槽位状态发生的变化而变化。对于每个原子对话来说,我们认为在用户提供了清晰的意图以及提供了全部的必填槽位信息之后,这个原子对话就算结束了,即可以触发 Function Calling 的指令。
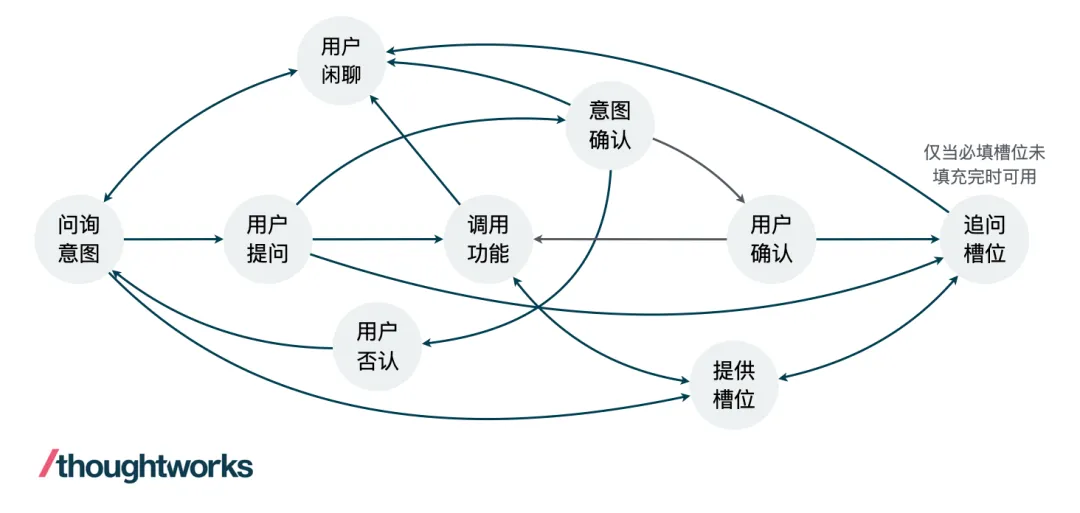
图 1. 对话流程转移图示例(可能没有覆盖全部场景)
2.初始状态随机生成
在对话系统的开始阶段,用户的首次提问可能包含从零到全部所需槽位的不同信息量。为了模拟这种多样性,我们可以使用蒙特卡洛方法来随机决定哪些槽位在用户的首次提问中被提及。具体来说,对于一个意图中的所有槽位,我们可以生成一个由 0 或 1 组成的随机数组,其中 0 表示该槽位不能再首次提问中提及,而 1 表示需要被提及。
例如,考虑一个酒店预订任务,可能的关键信息包括「入住日期」、「退房日期」 和 「房间类型」。利用上述的方法,我们可以为每个槽位生成一个对应的随机值,从而决定用户的首次提问中需要包含哪些信息。这不仅增加了对话样本的多样性,也使得训练数据集更加贴近真实世界的对话情况。
3.随机游走模拟用户行为
初始状态生成了之后,我们需要生成生成多样化的对话路径,这里采用蒙特卡洛方法使得当前的对话状态在建立好的对话转移状态图中随机游走。在每个状态完成之后,将随机选择下一个状态,各状态的转移概率可以根据经验进行定义,从而模拟用户可能采取的不同行动。例如,用户在首问中没有提供全部的必填槽位, Agent 将发起槽位的追问,对于 Agent 的追问,用户可能认真的回答槽位信息,也有可能发起闲聊,还有可能改变了主意,问了一个新的问题,不同的转移路径我们可以设置不同的概率,例如上面的转移路径我们根据经验分为设置概率为 [0.8, 0.1, 0.1]。
通过这种随机游走的方式,可以生成不同的对话状态路径,每条路径都代表了一种可能的用户行为和 Agent 响应。这些路径为我们提供了丰富的训练数据,帮助对话系统学习如何处理各种情况。
4.对上下文理解能力的增强
在实际对话中,用户通常不会在每个回合都重复提供所有相关信息。相反,他们会根据上下文,利用代词、省略或简化的表述来替代之前已经提及过的内容。为了让对话系统能够正确理解这种上下文依赖的表达方式,我们需要在训练数据中模拟这种用户行为模式。
具体来说,我们将对话分为多个阶段,每个阶段对应不同的任务意图。在后续阶段生成语料时,我们会考虑之前阶段已经提供的槽位信息。如果用户的新问题与之前的问题存在槽位重叠,且该槽位已在先前回合中提供过,那么在生成新问题时,我们将有意识地省略这部分信息,只保留用户需要补充的新信息。
例如,假设用户之前已经询问过「成都市内哪家火锅好吃」,这句话中包含了用户想要了解的位置和餐厅类型两个槽位信息。在后续对话中,如果用户想询问这些餐馆的价格区间,可能会使用「它们的价格大概是多少?」这样的省略式表述,而非重复提供完整的问句。通过模拟这种情况,我们可以增强模型对于上下文依赖的理解能力。
5.基于 LLM 的对话内容生成
LLM 在这一过程中扮演了至关重要的角色。我们利用 LLM 的强大生成能力来模拟用户的提问和系统的追问,生成接近真实对话的数据。例如,以推荐餐厅这个意图为例, 用于生成首问的 Prompt 可以这样写:
你是一个用户,你现在想要「根据自己的位置、兴趣和预算,让智能客服推荐当地的餐厅」,请向智能客服寻求帮助。
你的问题需要满足以下几个条件:
- 1在问题中需要提到具体的用户当前的区域或希望探索的区域。
- 在问题中一定不要提到具体的用户感兴趣的餐厅类型,中餐,日料,西餐等。
- 在问题中一定不要提到具体的用户的最大预算。
请生成一句满足当前的场景和设定的问题。
LLM 广阔的知识面为我们提供了丰富的语言资源,支持我们模拟各种场景的对话。此外,LLM 还能够根据上下文生成连贯且逻辑性强的回复,进一步提高了数据集的质量。
为了增强任务型对话 Agent 对领域信息的理解以及提高对话的多样性, RAG 技术将被用于为对话内容注入领域相关的知识。特别是在处理涉及特定领域业务的时候,领域知识在这一过程中至关重要。为了在实现领域信息的注入,以办理业务这个意图为例,可以采取以下实施步骤:
- 首先,提前准备好所有可以办理的业务列表以及每个业务对应的描述信息作为我们的候选信息源。
- 接着,在每次需要再对话中提及具体的业务功能的时候从这个槽位列表中随机选择一个或多个功能。例如,我们可以构建这样的 Prompt 「请生成一个用户想要办理 A 业务的话术,A 业务是一个 xxx 的功能」来生成不同的用户问题,一方面注入了我们想要 Agent 学习的领域知识,另一方面保证了对话语料的多样性。
通过这种方法,任务型对话代理可以更好地理解和响应用户需求,提供更精准和个性化的服务。
6.易扩展的意图配置
对于任务型 Agent 来说,对话的目标是一致,即收集足够的信息帮助用户执行任务。我们可以通过一个 YAML 文件来对任务的详细内容和槽位信息进行描述,用户意图增加和减少都可以通过编辑一系列 YAML 配置文件来实现,而无需对有状态转移图或生成流程进行复杂的更改。这种设计提高了本文方案的可扩展性。例如想生成一个根据地点,餐厅类型,最大预算推荐餐厅任务相关的数据集,只需要编写如下配置文件即可:
name: recommend_restaurant
description: 根据自己的位置、兴趣和预算,让智能客服推荐当地的餐厅
parameters:
- name: destination
description: 用户当前的区域或希望探索的区域。
type: text
required: True
- name: cuisine_type
description: 用户感兴趣的餐厅类型,中餐,日料,西餐等
type: text
required: True
- name: budget
description: 用户的最大预算
type: float
required: False分享说明:转发分享请注明出处。



