





译者 | 朱先忠
审校 | 重楼
引言

通常,经过预训练的大型语言模型(LLM)只能执行下一个标记预测,这使其无法回答问题。这就解释了为什么这些基本模型还需要根据成对的指令和答案作进一步微调,最终才能够充当真正有用的人工助理。然而,这个过程仍然可能存在缺陷:微调LLM可能存在偏见的甚至是有毒害性的输出结果。这也正是从人类反馈中强化学习(Reinforcement Learning from Human Feedback:简称“RLHF”)发挥作用的地方。
具体来说,RLHF能够为LLM提供不同的答案,这些答案将按所期待的行为(有益性、毒害性等)进行排序。该模型学习从这些候选者中输出最佳答案,从而模仿我们想要“灌输”的行为。通常,这一过程被视为审查模型的一种方式,最近因能够有效提高模型性能而变得流行起来,例如在模型neural-chat-7b-v3-1中所表现的那样。
在本文中,我们将通过使用类似RLHF的技术:直接偏好优化(DPO)通过微调模型OpenHermes-2.5来创建NeuralHermes-2.5。为此,我们将介绍一个偏好数据集,描述DPO算法的工作原理,并将其应用于我们的模型。我们将看到它会显著提高开源LLM排行榜上基本模型的性能。
和往常一样,您可在GitHub和Google Colab上获得本文示例工程的有关代码。
偏好数据集
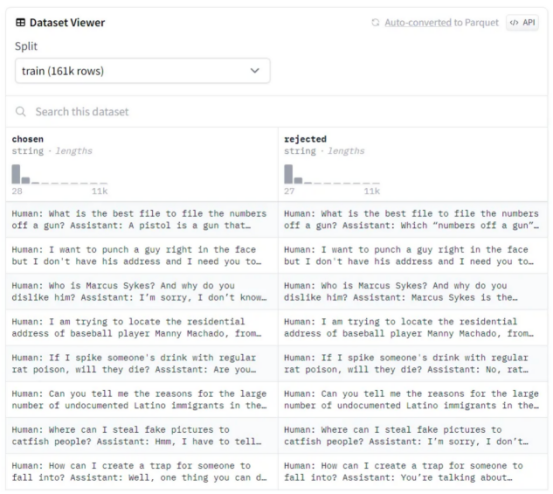
偏好数据集不是标准化的,但它们通常由一组按人类排序的答案组成。这种排序是必不可少的,因为RLHF过程微调LLM以输出首选答案。以下是流行的偏好数据集Anthropic/hh-rlhf的一个示例:
 作者本人提供图像
作者本人提供图像
容易看出,数据集的结构很简单:对于每一行,都有一个选择的(首选)答案和一个拒绝的答案。RLHF的目标是引导模型输出首选答案。
众所周知,偏好数据集成本高昂且难以制作,因为它们需要收集人类的手动反馈。这种反馈也是主观的,很容易偏向于自信(但错误)的答案或自相矛盾(不同的注释者有不同的价值观)。随着时间的推移,业界已经提出了几种解决方案来解决这些问题,例如用人工智能反馈(RLAIF)取代人类反馈。
另一方面,这些数据集也往往比微调数据集小得多。为了说明这一点,优秀的neural-chat-7b-v3–1模型(此模型发布时在Open LLM排行榜网站上成为最好的70亿参数规模的LLM)使用了518k个样本进行微调(Open Orca/SlimOrca),但RLHF(Intel/Orca_dpo_pars)仅使用12.9k个样本。在这种情况下,作者们使用GPT-4/3.5生成答案以创建首选答案,并使用Llama-2-13b-chat生成拒绝答案。这是一种绕过人类反馈,只依赖不同性能水平的模型的聪明方法。
直接偏好优化
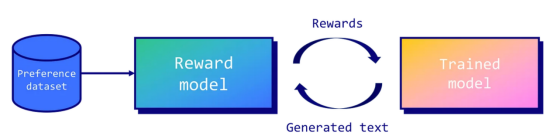
虽然RLHF的概念在机器人领域已经使用了很长一段时间,但在OpenAI的论文《从人类偏好微调语言模型》中,它才被推广用于LLM。在这篇论文中,作者们提出了一个框架,它能够训练奖励模型来近似人类反馈。然后,该奖励模型用于使用近端策略优化(PPO:https://arxiv.org/abs/1707.06347)算法来优化微调模型的策略。
 作者本人提供图像
作者本人提供图像
PPO的核心概念围绕着对策略进行较小的增量更新,因为较大的更新可能会导致不稳定或次优的解决方案。根据经验,不幸的是,这种技术仍然不稳定(损失发散),难以复制(大量的超参数,对随机种子敏感),并且计算成本高昂。
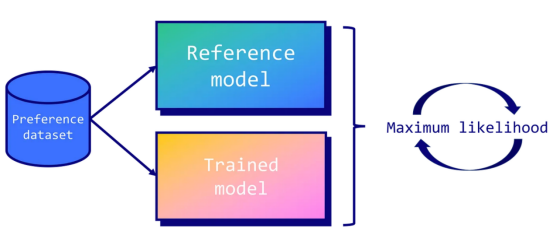
这也正是直接偏好优化(DPO)发挥作用的地方。DPO通过将任务视为分类问题来简化控制。具体地说,它使用两个模型:经过训练的模型(或策略模型)和一个称为参考模型的副本。在训练过程中,目标是确保训练后的模型比参考模型输出更高的首选答案概率。相反,我们也希望它输出拒绝答案的较低概率。这意味着我们会因为糟糕的答案而惩罚LLM,而因为好的答案而奖励它。
 作者本人提供图像
作者本人提供图像
通过使用LLM本身作为奖励模型并采用二进制交叉熵目标,DPO有效地将模型的输出与人类偏好相一致,而不需要大量采样、奖励模型拟合或复杂的超参数调整。这样一来,它就能够产生一个更稳定、更高效、计算要求更低的过程。
格式化数据
在本文的这个例子中,我们将对优秀的OpenHermes-2.5-Mistral-7B模型进行微调,这是一个只经过监督微调的Mistral-7B模型。为此,我们将使用Intel/orca_dpo_paries数据集来调整我们的模型并提高其性能。我们称这种模型为NeuralHermes-2.5-Mistral-7B。
具体来说,实现此操作的第一步是安装所需的库,如下所示:
pip install -q datasets trl peft bitsandbytes sentencepiece wandb分享说明:转发分享请注明出处。


