





前段时间,AI大神Karpathy上线的AI大课,已经收获了全网15万次播放量。
当时还有网友表示,这2小时课程的含金量,相当于大学4年。

就在这几天,Karpathy又萌生了一个新的想法:
那便是,将2小时13分钟的「从头开始构建GPT分词器」的视频,转换为一本书的章节(或者博客文章)形式,专门讨论「分词」。
具体步骤如下:
- 为视频添加字幕或解说文字。
- 将视频切割成若干带有配套图片和文字的段落。
- 利用大语言模型的提示工程技术,逐段进行翻译。
- 将结果输出为网页形式,其中包含指向原始视频各部分的链接。
更广泛地说,这样的工作流程可以应用于任何视频输入,自动生成各种教程的「配套指南」,使其格式更加便于阅读、浏览和搜索。
这听起来是可行的,但也颇具挑战。
他在GitHub项目minbpe下,写了一个例子来阐述自己的想象。
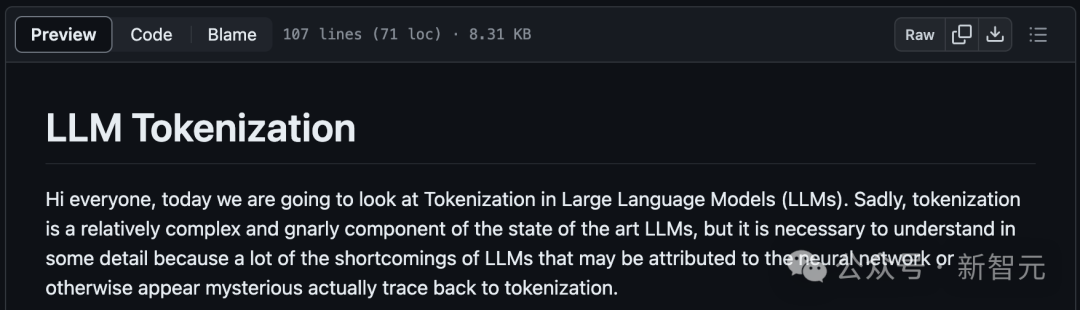
地址:https://github.com/karpathy/minbpe/blob/master/lecture.md
Karpathy表示,这是自己手动完成的任务,即观看视频并将其翻译成markdown格式的文章。
「我只看了大约4分钟的视频(即完成了3%),而这已经用了大约30分钟来写,所以如果能自动完成这样的工作就太好了」。
接下来,就是上课时间了!
「LLM分词」课程文字版
大家好,今天我们将探讨LLM中的「分词」问题。
遗憾的是,「分词」是目前最领先的大模型中,一个相对复杂和棘手的组成部分,但我们有必要对其进行详细了解。
因为LLM的许多缺陷可能归咎于神经网络,或其他看似神秘的因素,而这些缺陷实际上都可以追溯到「分词」。
字符级分词
那么,什么是分词呢?
事实上,在之前的视频《让我们从零开始构建 GPT》中,我已经介绍过分词,但那只是一个非常简单的字符级版本。
如果你去Google colab查看那个视频,你会发现我们从训练数据(莎士比亚)开始,它只是Python中的一个大字符串:
First Citizen: Before we proceed any further, hear me speak.
All: Speak, speak.
First Citizen: You are all resolved rather to die than to famish?
All: Resolved. resolved.
First Citizen: First, you know Caius Marcius is chief enemy to the people.
All: We know't, we know't.分享说明:转发分享请注明出处。



