





Gemini是谷歌开发的一个新模型。有了Gemini可以为查询提供图像、音频和文本,获得几乎完美的答案。
我们在本教程中将学习Gemini API以及如何在机器上设置它。我们还将探究各种Python API函数,包括文本生成和图像理解。
Gemini AI模型介绍
Gemini是谷歌研究院和谷歌DeepMind等团队合作开发的新型AI模型。它为多模态而建,理解并处理不同类型的数据,比如文本、代码、音频、图像和视频。
Gemini是谷歌迄今为止开发的最先进、最庞大的AI模型。它非常灵活,可以从数据中心到移动设备的各种系统上高效运行。这意味着它有望彻底改变企业和开发人员构建和扩展AI应用程序的方式。
以下是针对不同用例设计的Gemini模型的三个版本:
- Gemini Ultra:最庞大最先进的AI,能够执行复杂的任务。
- Gemini Pro:一种良好性能和可扩展性兼备的模型。
- Gemini Nano:最适合移动设备。
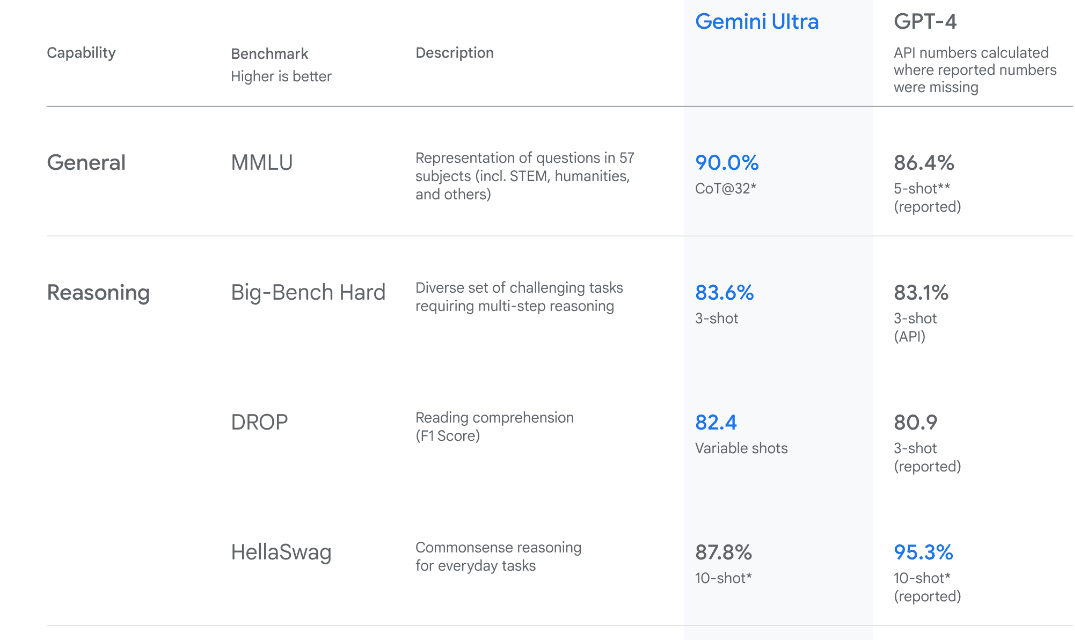
Gemini Ultra具有最先进的性能,在几个指标上超过了GPT-4的性能。它是第一个在大规模多任务语言理解基准测试中超越人类专家的模型,该基准测试57个不同学科的世界知识和解决问题的能力。这展示了其先进的理解和解决问题的能力。
设置
要使用API,我们必须先获得一个API密钥,可以从这里获取:https://ai.google.dev/tutorials/setup。
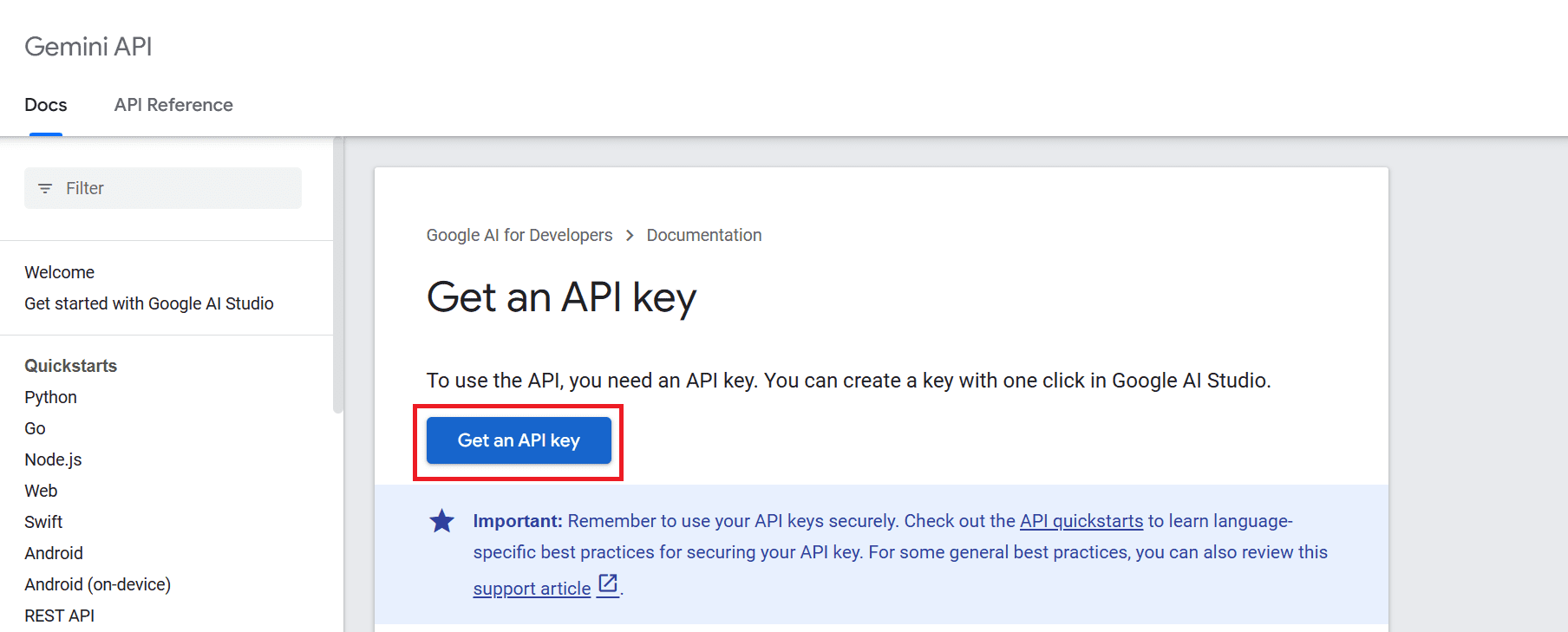
然后,点击“获取API密钥”按钮,随后点击“在新项目中创建API密钥”。
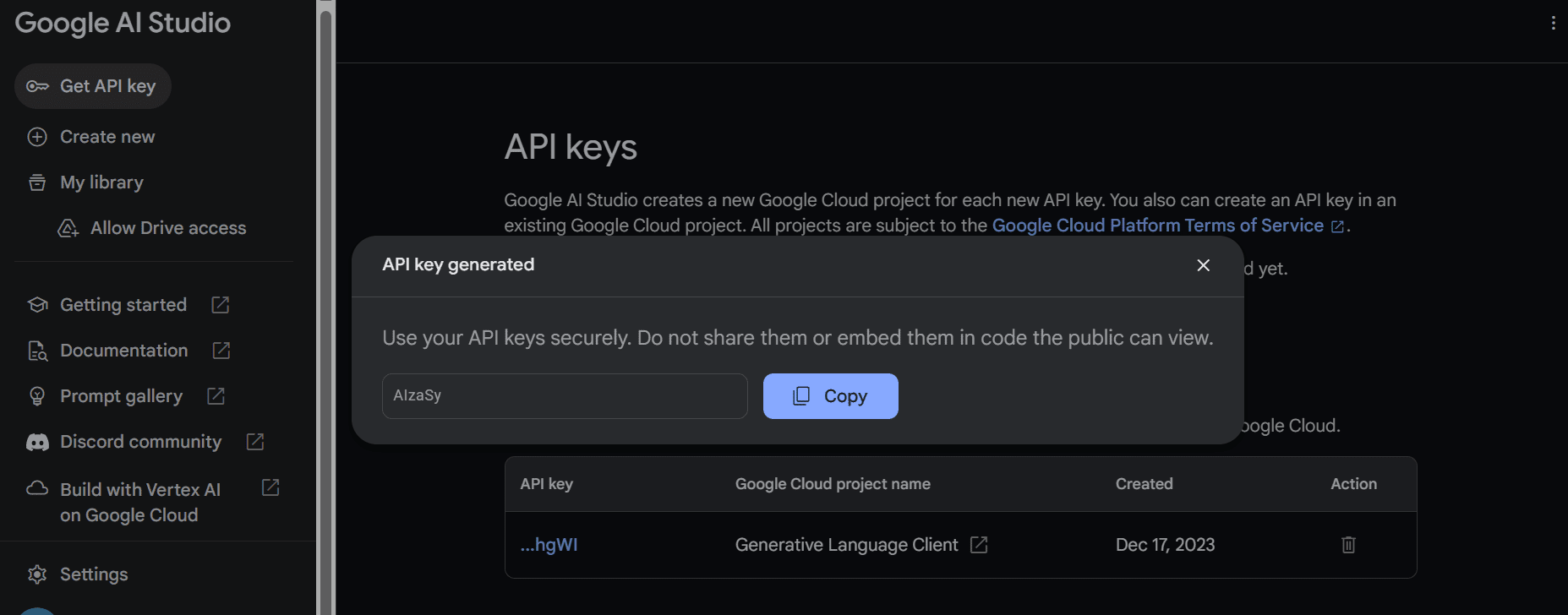
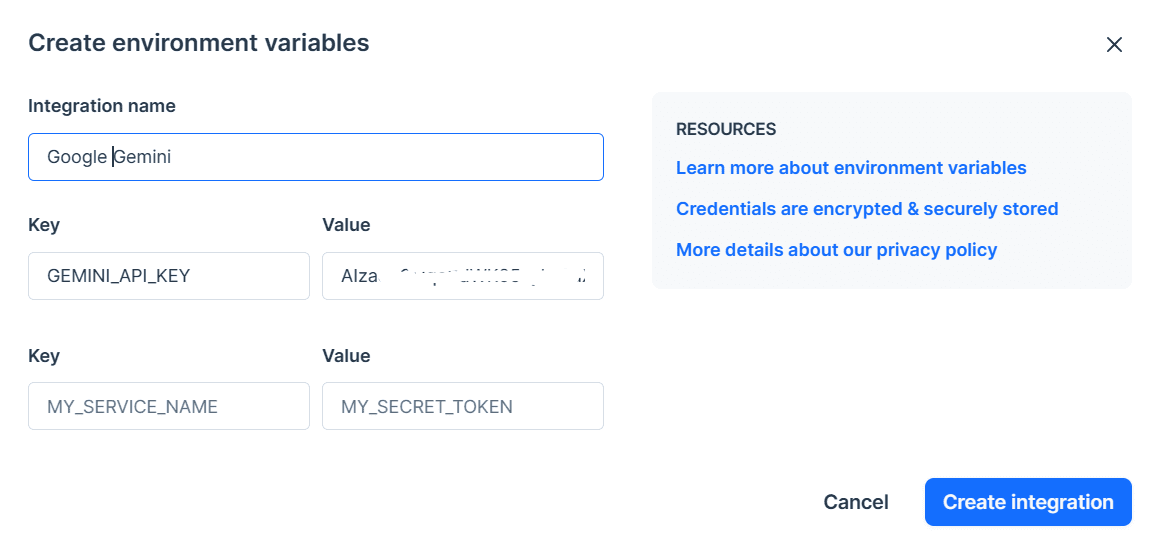
复制API密钥并将其设置为环境变量。我们使用Deepnote,很容易设置名为“GEMINI_API_KEY”的密钥。只要转入到集成,向下滚动并选择环境变量。
在下一步中,我们将使用PIP安装Python API:
pip install -q -U google-generativeai分享说明:转发分享请注明出处。



