





在2022年11月OpenAI的ChatGPT发布之后,大型语言模型(llm)变得非常受欢迎。从那时起,这些语言模型的使用得到了爆炸式的发展,这在一定程度上得益于HuggingFace的Transformer库和PyTorch等库。
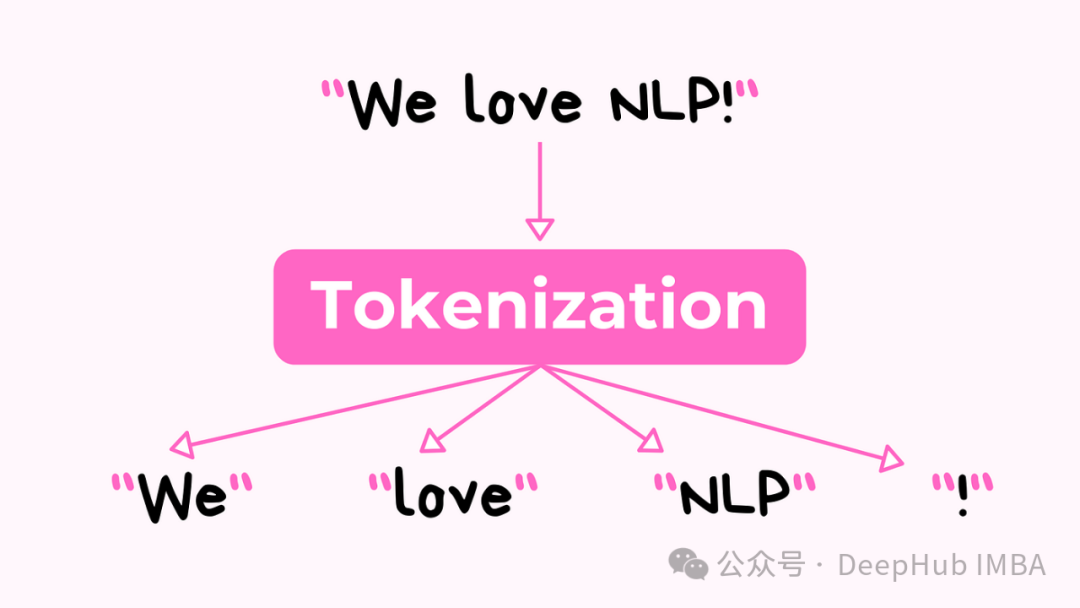
计算机要处理语言,首先需要将文本转换成数字形式。这个过程由一个称为标记化 Tokenization。
标记化分为2个过程:
1、将输入文本划分为token
标记器首先获取文本并将其分成更小的部分,可以是单词、单词的部分或单个字符。这些较小的文本片段被称为标记。Stanford NLP Group[2]将标记更严格地定义为:
在某些特定的文档中,作为一个有用的语义处理单元组合在一起的字符序列实例。
2、为每个标记分配一个ID
标记器将文本划分为标记后,可以为每个标记分配一个称为标记ID的整数。例如,单词cat被赋值为15,因此输入文本中的每个cat标记都用数字15表示。用数字表示替换文本标记的过程称为编码。类似地将已编码的记号转换回文本的过程称为解码。
使用单个数字表示记号有其缺点,因此要进一步处理这些编码以创建词嵌入,这个不在本文的范围内,我们后面介绍。
标记方法
将文本划分为标记的主要方法有三种:
1、基于单词:
基于单词的标记化是三种标记化方法中最简单的一种。标记器将通过拆分每个空格字符(有时称为“基于空白的标记化”)或通过类似的规则集(如基于标点的标记化)将句子分成单词[12]。
例如,这个句子:
Cats are great, but dogs are better!分享说明:转发分享请注明出处。


