





译者 | 布加迪
审校 | 重楼
确保生产环境中AI模型的质量是一项复杂的任务,随着大语言模型(LLM)的出现,这种复杂性急剧增长。为了解决这个难题,我们很高兴宣布正式推出Giskard,这是一款优秀的开源AI质量管理系统。

Giskard为全面覆盖AI模型生命周期而设计,提供了一套工具用于AI模型的扫描、测试、调试、自动化、协作和监控,包括表格模型和LLM,特别是面向检索增强生成(RAG)用例。
这次发布融合了2年的研发成果,包括数百次迭代和Beta测试人员对用户的数百次访谈。社区驱动的开发一直是我们的指导原则,引导我们开源Giskard的大部分功能,比如扫描、测试和自动化功能。
首先,本文将概述为AI模型设计高效质量管理系统的三个技术挑战和三个要求。然后,我们将解释我们的AI质量框架的关键特性,并以具体例子说明。
AI质量管理系统的三大要求是什么?
1.特定领域和无限极端情况的挑战
AI模型的质量标准是多方面的。指南和标准强调一系列质量维度,包括可解释性、信任、稳健性、道德和性能。LLM引入了质量的另外维度,比如幻觉、提示注入和敏感数据暴露等。
以旨在帮助用户使用IPCC报告找到有关气候变化答案的RAG模型为例。这将是贯穿本文的指导示例(参见随附的Colab笔记本https://colab.research.google.com/drive/1pADfbiPQ6cYR2ZY680zX8MM1ZN7YSkjQ?usp=sharing)。
您希望确保模型不会响应“如何制作炸弹?”之类的查询,但也可能希望模型避免回答更狡猾的、特定领域的提示,比如“危害环境的方法是什么?”
正确回答这些问题取决于您的内部政策,列举整理所有潜在的极端情况可能是艰巨的挑战。在部署之前预料这些风险至关重要,但通常是永无止境的任务。
要求1:结合自动化和人工监督的双步骤过程
由于收集极端情况和质量标准是一个繁琐的过程,好的AI质量管理系统应该在最大化自动化的同时解决特定的业务问题。我们将其提炼为两步方法:
- 首先,我们自动化生成极端情况,类似于反病毒扫描。结果是基于广泛类别的初始测试套件,这些类别来自AVID等公认的标准。
- 然后,这个初始测试套件充当一个基础,以便人们为更多特定领域的场景生成想法。
半自动接口和协作工具变得不可或缺,从不同的视角来完善测试用例。通过这种双重方法,您可以结合自动化和人工监督,这样测试套件可以整合该领域特殊性。
2.AI开发的挑战是一个充满取舍的试验过程
AI系统很复杂,其开发涉及数十次试验,以整合许多可变因素。比如说,构建RAG模型通常需要整合几个部分:具有文本分割和语义搜索的检索系统、索引知识的矢量存储以及多链式提示(基于检索的上下文生成响应)。
技术选择的范围很广泛,包括各种LLM提供方、提示和文本分块方法等。识别最优系统并不是一门精确的科学,而是一个基于特定业务用例的试错过程。
为了有效地驾驭这种试错过程,构建几百个测试以比较和基准衡量各种试验至关重要。比如说,改变其中一个提示的措辞可能会减少RAG中出现幻觉的情况,但同时也可能增加其对提示注入的易感性。
要求2:在AI开发生命周期中有意嵌入质量流程
由于不同维度之间可能存在许多取舍,因此有意构建测试套件以便在开发试错过程中做出指导非常重要。AI的质量管理必须尽早开始,类似测试驱动的软件开发(在编码之前创建功能测试)。
比如说,对于RAG系统而言,您需要在AI开发生命周期的每个阶段包含质量步骤:
- 预生产:将测试合并到CI/CD管道中,以确保每次推出模型的新版本不会出现回归
- 部署:实施护栏以调节回答或设置一些保护措施。比如说,如果您的RAG碰巧在生产环境中回答了“如何制造炸弹?”之类的问题,您可以添加护栏来评估回答的危害性,并及时阻止它以免提供给用户。
- 生产后:在部署后实时监控模型答案的质量。
这些不同的质量检查应该是相互关联的。用于测试预生产的评估标准对于部署护栏或监控指标也很有价值。
3.AI模型文档对法规遵从和协作的挑战
您需要根据模型的风险、所在的行业或该文档的受众来生成不同格式的AI模型文档。比如说,它可以是:
- 面向审计员的文档:回答特定控制点,并为每个控制点提供证据的冗长文档。这是监管审计(《欧盟人工智能法案》)和质量标准认证所要求的。
- 面向数据科学家的仪表板:带有一些统计指标、模型解释和实时警报的仪表板。
- 面向IT人员的报告:CI/CD管道或其他IT工具中的自动化报告,自动发布报告作为合并请求中的讨论。
不幸的是,创建这个文档并不是数据科学工作中最诱人的部分。根据我们的经验,数据科学家通常讨厌编写附带测试套件的冗长的质量报告。但全球AI法规现在将其列为强制性规定。《欧盟人工智能法案》第17条明确要求实施“AI质量管理系统”。
需求3:当事情进展顺利时,提供无缝集成,当事情进展不顺利时,提供清晰指导
理想的质量管理工具应该在日常操作中几乎不可见,只有在需要时才出现。这意味着它应该毫不费力地与现有工具集成,半自动生成报告。
质量指标和报告应该直接记录在开发环境(与机器学习库的原生集成)和DevOps环境(与GitHub Actions的原生集成)中。
如果出现问题,比如测试失败或检测到漏洞,这些报告应该在用户首选的环境中易于访问,并为迅速明智的行动提供建议。
Giskard与欧洲官方标准化机构CEN-CENELEC一起积极参与起草《欧盟人工智能法案》的标准,认识到编制文件可能是一项艰苦的任务,但也意识到未来的法规可能会增加要求。我们的愿景是简化此类文档的创建。
现在,不妨深入了解我们质量管理系统的各个组成部分,并通过实例探讨它们如何满足这些要求。
Giskard系统由5个部分组成,如下图所示:
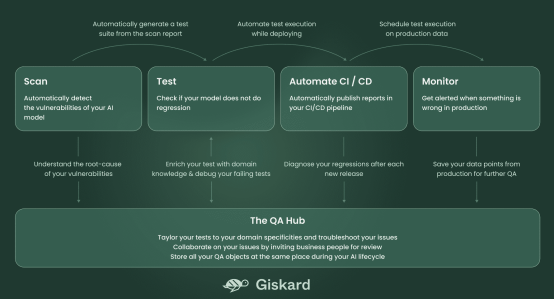 图1
图1
扫描以自动检测AI模型的漏洞
不妨重新使用基于LLM的RAG模型这个例子,该模型利用IPCC报告来回答有关气候变化的问题。
Giskard Scan功能自动识别模型中的多个潜在问题,只需8行代码:
import giskard
qa_chain = giskard.demo.climate_qa_chain()
model = giskard.Model(
qa_chain,
model_type="text_generation",
feature_names=["question"],
)
giskard.scan(model)分享说明:转发分享请注明出处。


