





评估聚类结果的有效性,即聚类评估或验证,对于聚类应用程序的成功至关重要。它可以确保聚类算法在数据中识别出有意义的聚类,还可以用来确定哪种聚类算法最适合特定的数据集和任务,并调优这些算法的超参数(例如k-means中的聚类数量,或DBSCAN中的密度参数)。
虽然监督学习技术有明确的性能指标,如准确性、精度和召回率,但评估聚类算法更具挑战性:
由于聚类是一种无监督学习方法,因此没有可以比较聚类结果的基础真值标签。

确定“正确”簇数量或“最佳”簇通常是一个主观的决定,即使对领域专家也是如此。一个人认为是有意义的簇,另一个人可能会认为是巧合。
在许多真实世界的数据集中,簇之间的界限并不明确。一些数据点可能位于两个簇的边界,可以合理地分配给两个簇。
不同的应用程序可能优先考虑簇的不同方面。例如,在一个应用程序中,可能必须有紧密、分离良好的簇,而在另一个应用程序中,捕获整体数据结构可能更重要。
考虑到这些挑战,通常建议结合使用评估指标、视觉检查和领域专业知识来评估簇性能。
一般来说,我们使用两种类型的聚类评估度量(或度量):
内部:不需要任何基础事实来评估簇的质量。它们完全基于数据和聚类结果。
外部:将聚类结果与真值标签进行比较。(因为真值标签在数据中是没有的,所以需要从外部引入)
通常,在实际的应用程序中,外部信息(如真值标签)是不可用的,这使得内部度量成为簇验证的唯一可行选择。
在本文中,我们将探讨聚类算法的各种评估指标,何时使用它们,以及如何使用Scikit-Learn计算它们。
内部指标
由于聚类的目标是使同一簇中的对象相似,而不同簇中的对象不同,因此大多数内部验证都基于以下两个标准:
紧凑性度量:同一簇中对象的紧密程度。紧凑性可以用不同的方法来衡量,比如使用每个簇内点的方差,或者计算它们之间的平均成对距离。
分离度量:一个簇与其他簇的区别或分离程度。分离度量的例子包括簇中心之间的成对距离或不同簇中对象之间的成对最小距离。
我们将描述三种最常用的内部度量方法,并讨论它们的优缺点。
1、轮廓系数
轮廓系数(或分数)通过比较每个对象与自己的聚类的相似性与与其他聚类中的对象的相似性来衡量聚类之间的分离程度[1]。
我们首先定义数据点x的轮廓系数为:

这里的A (x′)是x′到簇中所有其他数据点的平均距离。或者说 如果点x∈属于簇C∈,那么
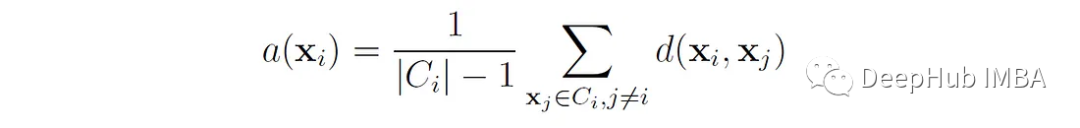
其中d(x, xⱼ)是点x和x之间的距离ⱼ。我们可以将a(x ^ e)解释为点x ^ e与其自身簇匹配程度的度量(值越小,匹配越好)。对于大小为1的簇,a(x′f)没有明确定义,在这种情况下,我们设s(x′f) = 0。
B (x′)是x′与相邻簇中点之间的平均距离,即点到x′的平均距离最小的簇:

轮廓系数的取值范围为-1到+1,值越高表示该点与自己的聚类匹配得越好,与邻近的聚类匹配得越差。
基于样本的轮廓系数,我们现在将轮廓指数(SI)定义为所有数据点上系数的平均值:

这里的n为数据点总数。
轮廓系数提供了对聚类质量的整体衡量:
接近1意味着紧凑且分离良好。
在0附近表示重叠。
接近-1表示簇的簇太多或太少。
sklearn的Metrics提供了许多聚类评估指标,为了演示这些指标的使用,我们将创建一个合成数据集,并使用不同的k值对其应用k-means聚类。然后,我们将使用评估指标来比较这些聚类的结果。
首先使用make_blobs()函数从3个正态分布的聚类中随机选择500个点生成一个数据集,然后对其进行归一化,以确保特征具有相同的尺度:
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
X, y = make_blobs(n_samples=500, centers=3, cluster_std=0.6, random_state=0)
X = StandardScaler().fit_transform(X)分享说明:转发分享请注明出处。



